Author: Andrey
-
Custom CUDA and Python

Just-in-time (JIT) compilation and Python bindings for interfacing with NVIDIA CUDA. Go to article…
-
Analog AI

A look at the status of analog deep learning inference and training technologies. Go to article…
-
Narrow Bit-Width Formats for Deep Learning
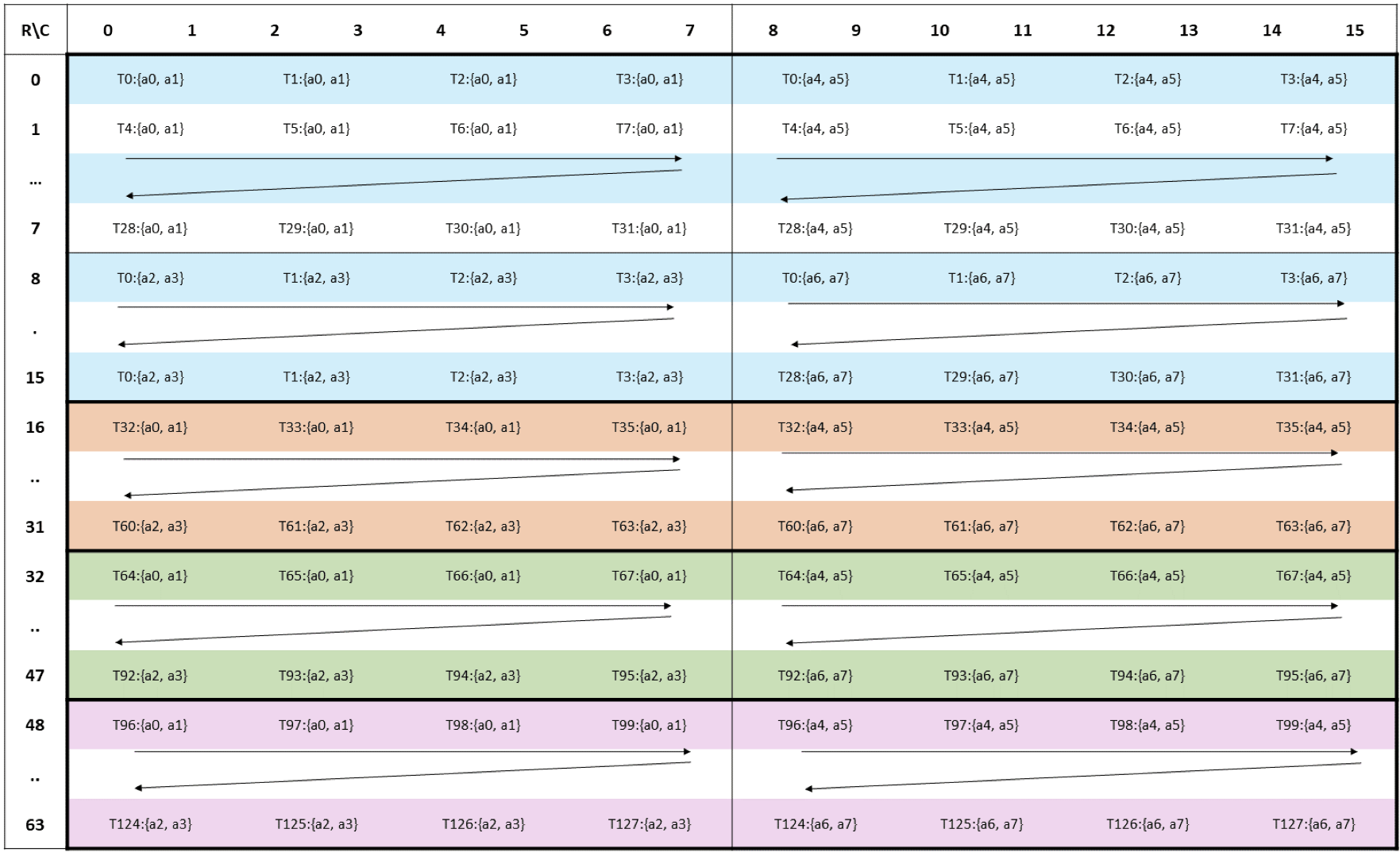
New number formats with precision less than FP32 allow for faster and more power-efficient deep learning. Go to article…
-
Proxmox VE

Proxmox Virtual Environment (Proxmox VE) is an open-source virtualization platform that integrates multiple open-source technologies. Go to article…
-
Software Pipelining in the NVIDIA Hopper Architecture

C++ Software Pipelining Template for overlapping TMA and GEMM operations on the NVIDIA Hopper architecture. Go to article…
-
JSON Web Token Standard (JWT)

JSON Web Tokens are an open, industry standard RFC 7519 method for representing claims securely between two parties. Go to article…
-
SPEC Benchmarks
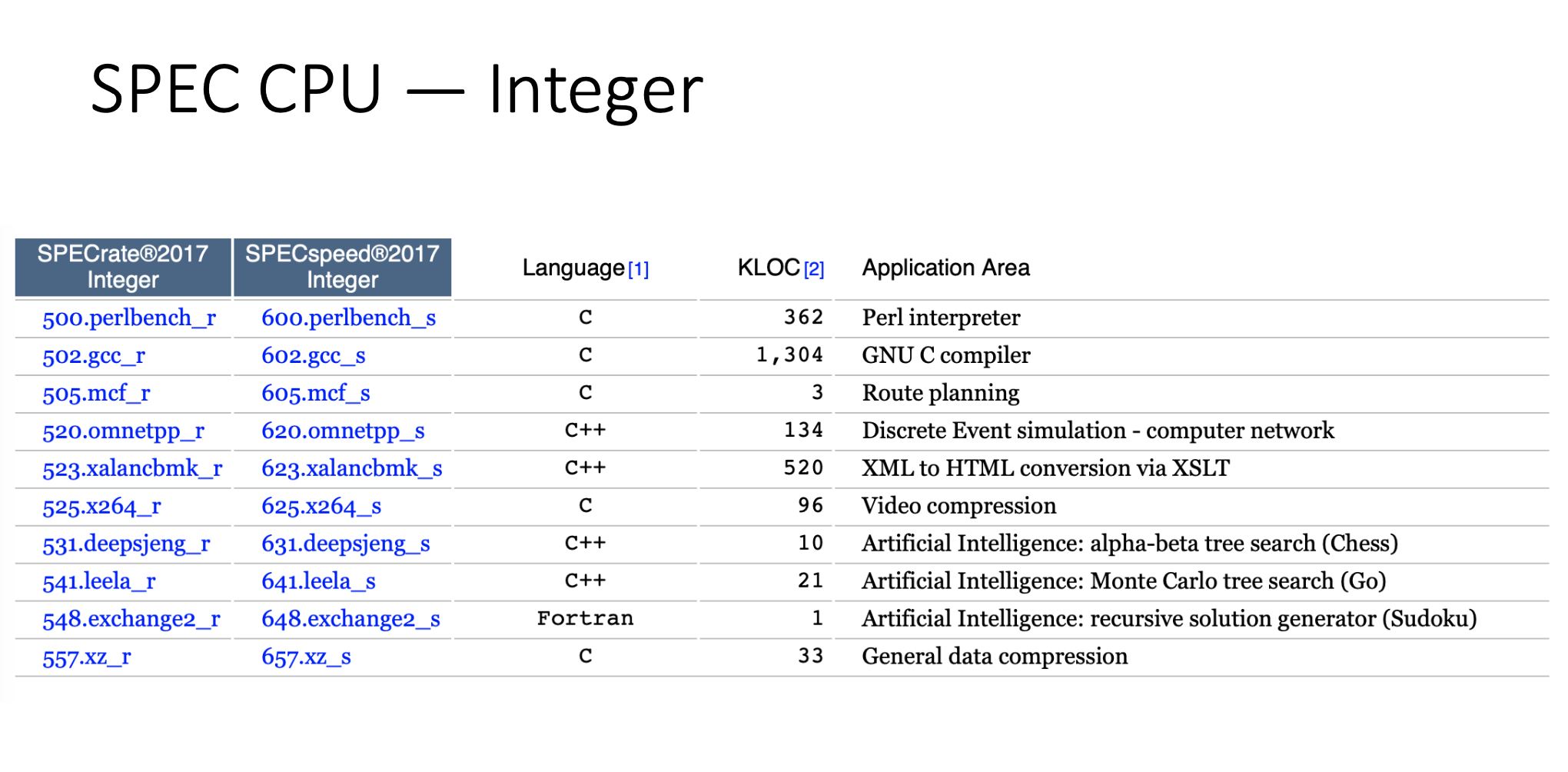
Industry-standardized, CPU intensive suites for measuring and comparing compute intensive performance, stressing a system’s processor, memory subsystem and compiler. Go to article…