Author: Jay
-
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
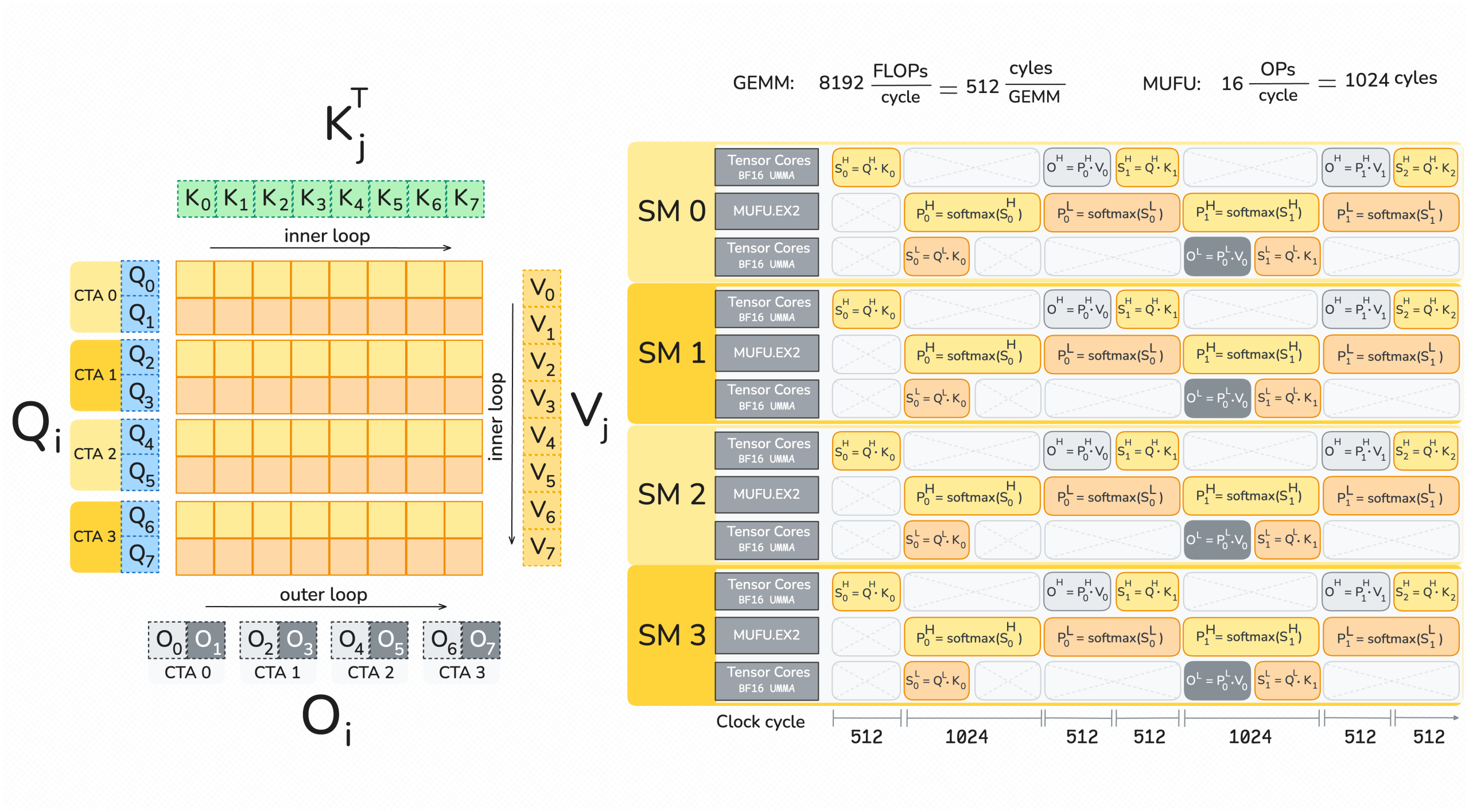
Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core… Go to article…
-
Categorical Foundations for CuTe Layouts
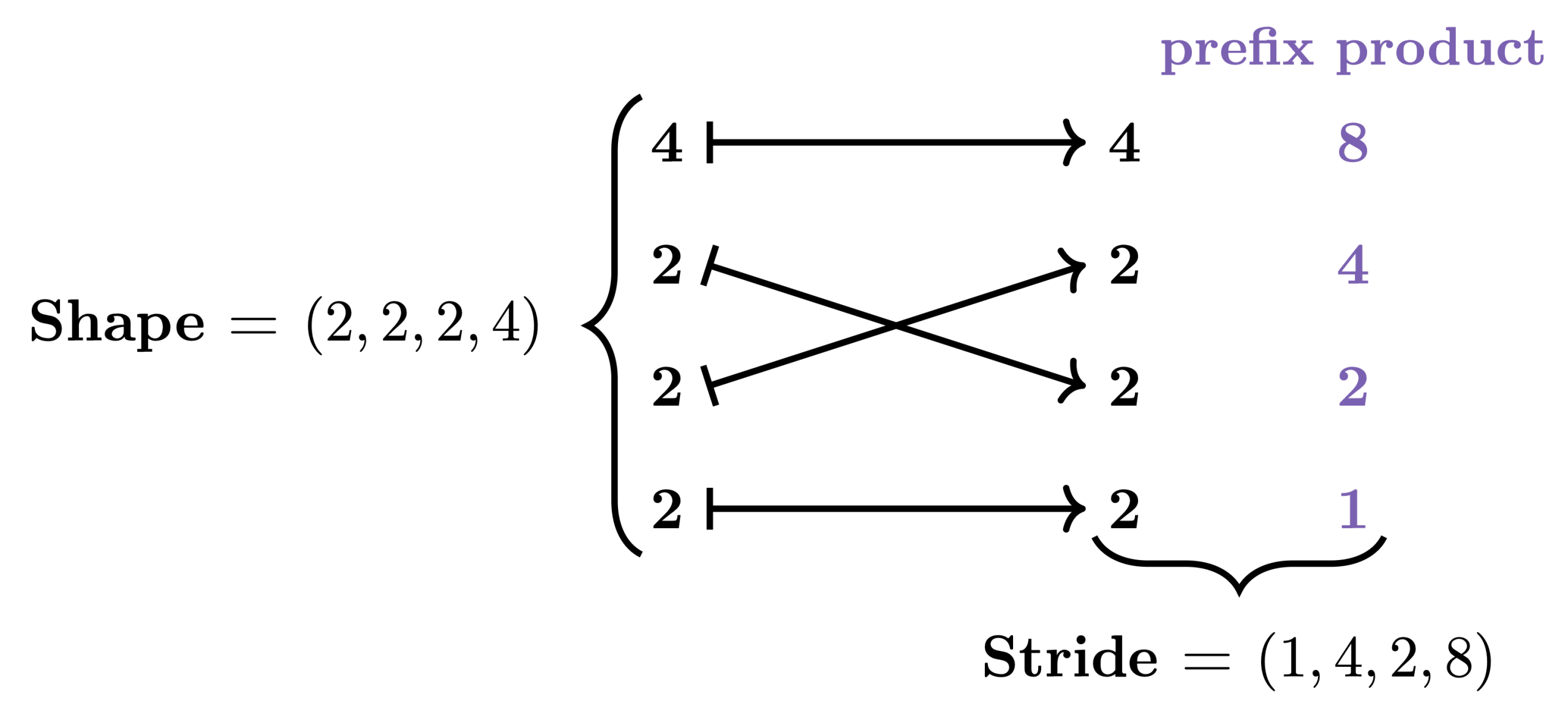
In GPU programming, performance depends critically on how data is stored and accessed in memory. While the data we care about is typically multi-dimensional, the GPU’s memory is fundamentally one-dimensional. This means that when we want to load, store, or otherwise manipulate data, we need to map its multi-dimensional logical coordinates to one-dimensional physical coordinates. Go to article…
-
CUTLASS 3.x APIs: Orthogonal, Reusable, and Composable Abstractions for GEMM Kernel Design (External)
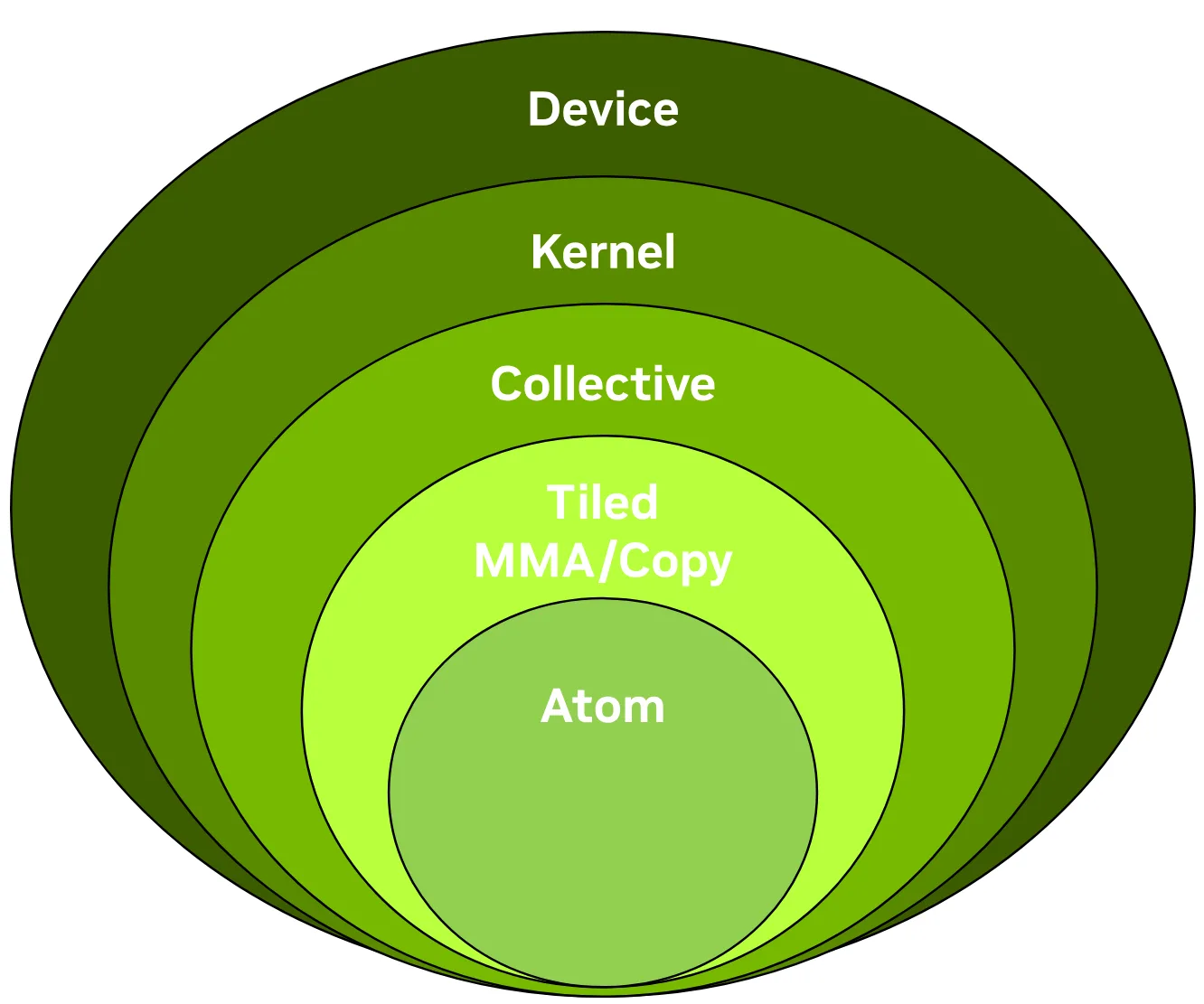
In this blog post presented on the NVIDIA technical blog, we give a concise introduction to the CUTLASS 3.x APIs, focusing on the collective, kernel, and device layers and the functionality of the collective builders. This post was authored in conjunction with members of the CUTLASS team. Go to article…
-
FlashAttention-3 for Inference: INT8 Quantization and Query Head Packing for MQA/GQA (External)

In this blog post presented on the Character.AI research blog, we explain two techniques that are important for using FlashAttention-3 for inference: in-kernel pre-processing of tensors via warp specialization and query head packing for MQA/GQA. Go to article…
-
Introduction to Transformers
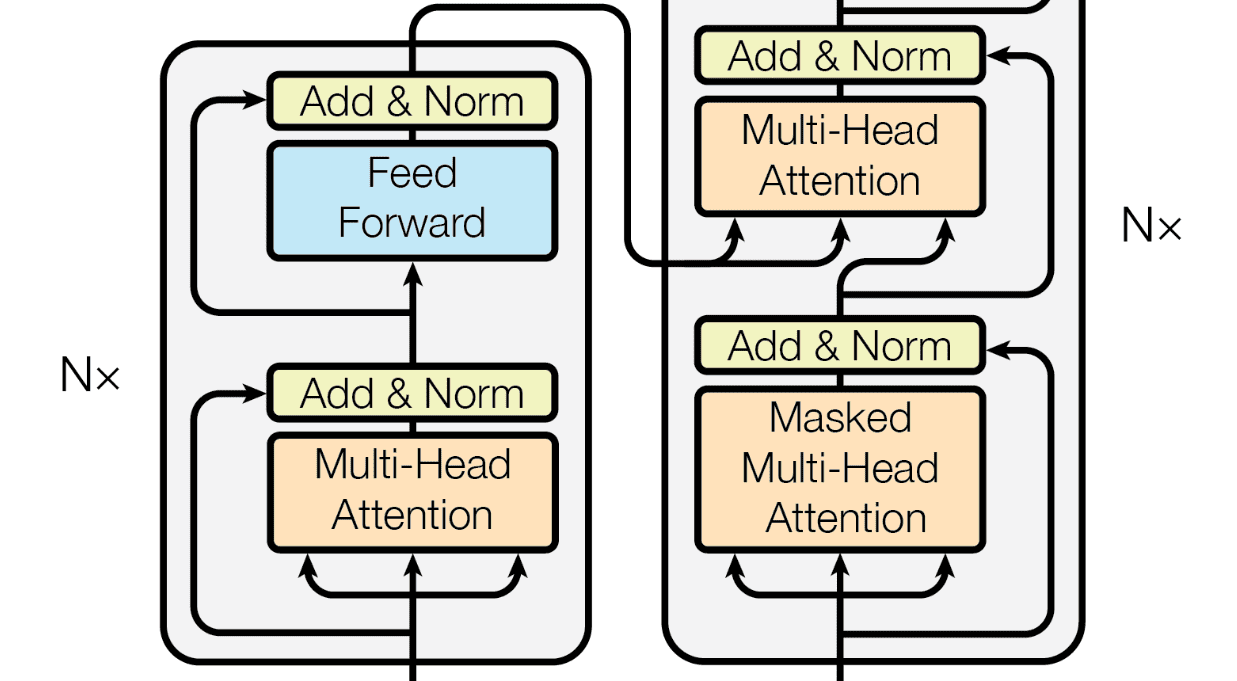
An introduction to the transformer architecture and the attention mechanism lying at its heart, following the famous paper “Attention Is All You Need” by Vaswani et. al. Go to article…
-
A note on the algebra of CuTe Layouts

The core abstraction of NVIDIA’s CUTLASS library for high-performance linear algebra is the CuTe Layout. In this technical note, we give a rigorous, mathematical treatment of the algebra of these layouts and certain layout operations. Currently, the main goal is to lay down conditions for when the operations of complementation, composition, and logical division are Go to article…
-
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library
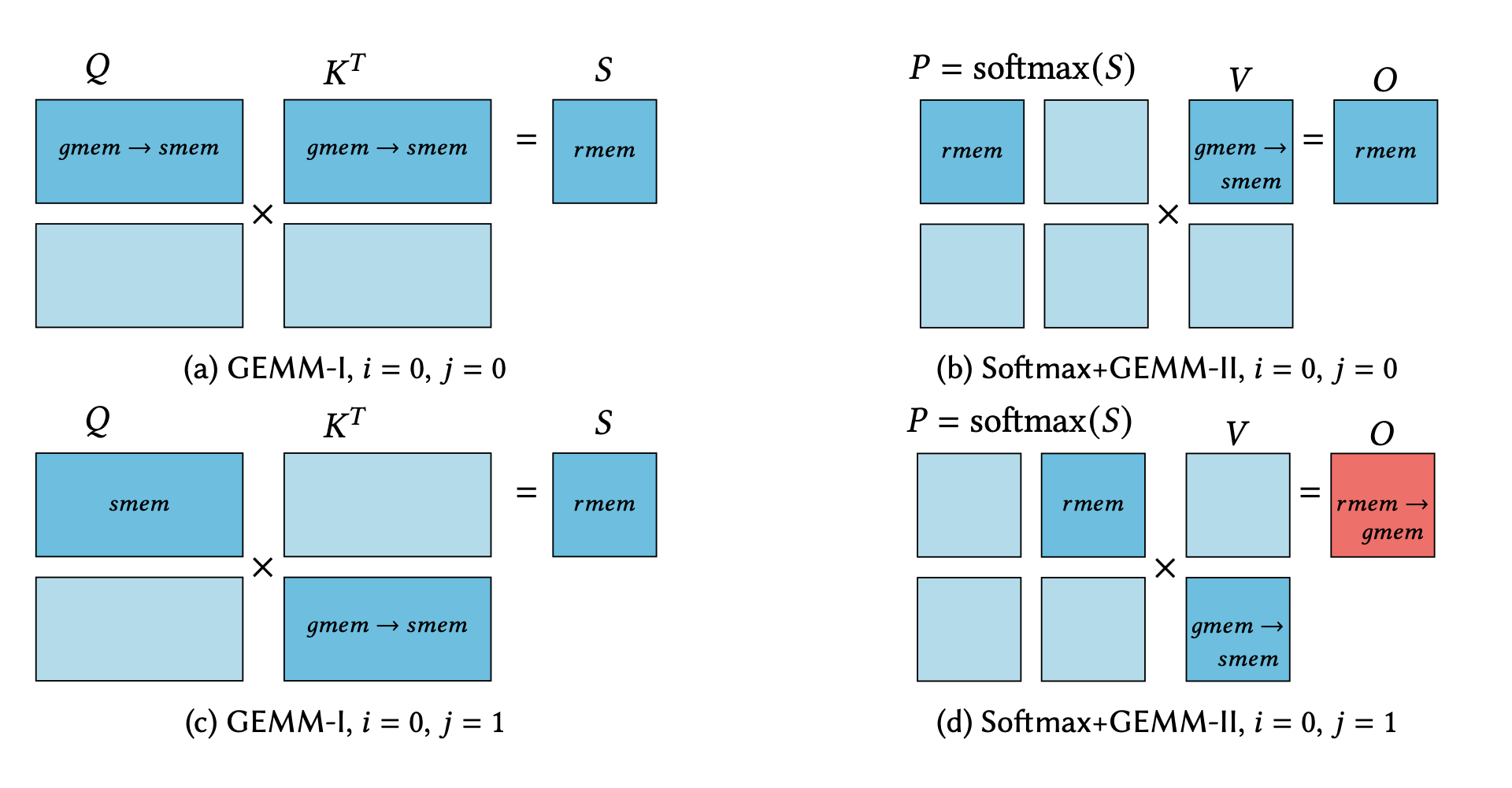
We provide an optimized implementation of the forward pass of FlashAttention-2, a popular memory-aware scaled dot-product attention algorithm, as a custom fused CUDA® kernel targeting NVIDIA Hopper™ architecture and written using the open-source CUTLASS library. In doing so, we explain the challenges and techniques involved in fusing online-softmax with back-to-back GEMM kernels, utilizing the Hopper-specific Go to article…
-
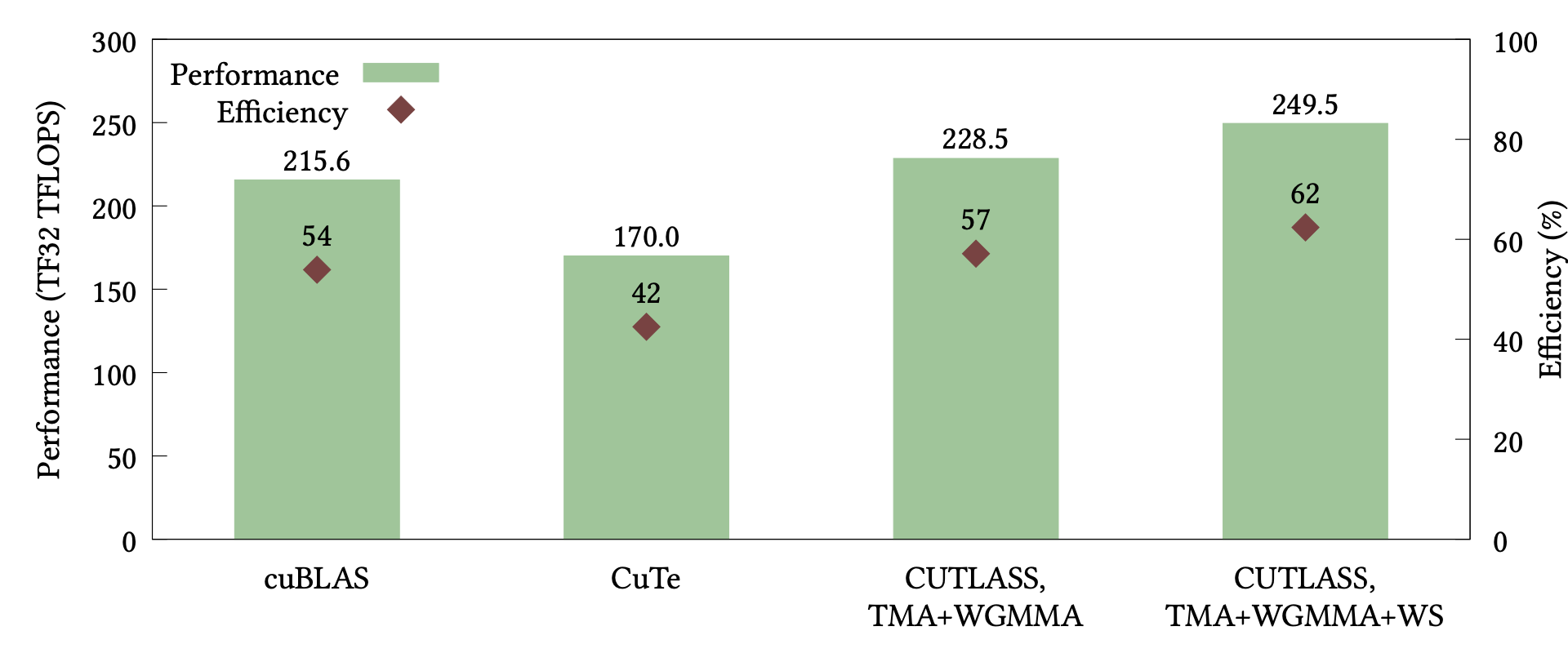
Developing CUDA Kernels for GEMM on NVIDIA Hopper Architecture using CUTLASS
We explain how to develop NVIDIA CUDA® kernels for optimized general matrix multiplication (GEMM) on NVIDIA Hopper™ architecture using the template collection CUTLASS and its core library CuTe. Our main contribution is to provide an implementation of a GEMM kernel that uses the Tensor Memory Accelerator (TMA) and Warp Group Matrix-Multiply-Accumulate (WGMMA) operations introduced with… Go to article…