We present expository-style articles and coding tutorials on our blog.
-
NVFP4 Blockscaled GEMM on NVIDIA RTX Pro Blackwell GPUs (SM12x)

In this article, we explore hardware-supported NVFP4 blockscaled GEMM on SM12x GPUs, such as the NVIDIA RTX Pro 6000 Blackwell Server Edition (SM120) or NVIDIA DGX Spark (SM121). We will first discuss features of these GPUs and their kernel programming paradigm, situating them relative to SM10x (e.g. B200 or B300) and SM8x (Ampere/Ada). Then, we will discuss sub-byte blockscaled GEMM on… Go to article…
-
Dynamic persistent tile scheduling with Cluster Launch Control (CLC) on NVIDIA Blackwell GPUs

This blog post discusses Cluster Launch Control (CLC), a hardware-supported feature on NVIDIA Blackwell GPUs that facilitates optimal tile scheduling, in particular with respect to load balancing. To provide context, we first survey a few common scheduling strategies and the deficiencies CLC is designed to address. We then walk through the implementation-level details of using CLC in a CuTe DSL… Go to article…
-
FlexAttention + FlashAttention-4: Fast and Flexible (External)

In this PyTorch blog on which we collaborated, we explain the FlexAttention extension to FlashAttention-4 (or from another point of view, the incorporation of FA-4 as an attention backend for the PyTorch FlexAttention API). Go to article…
-
CUTLASS Tutorial: Hardware-supported Block-scaling with NVIDIA Blackwell GPUs

Welcome to part 4 of our series investigating GEMM on the NVIDIA Blackwell architecture. So far we have discussed the capabilities of the new Blackwell Tensor Core UMMA instructions, including handling sub-byte data types, and how to work with them in CUTLASS. In this part, we will continue our exploration of low-precision computation by discussing how to utilize the blockscaling… Go to article…
-
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling

Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core throughput increases from 1 to… Go to article…
-
A User’s Guide to FlexAttention in FlashAttention CuTe DSL

Many variants of attention (Vaswani et al., 2017) have become popular in recent years, for reasons related to performance and model quality. These include: The PyTorch team at Meta recognized that most of these variants (including all of the above) can be unified under one elegant framework, dubbed FlexAttention (Guessous et al., 2024). This simple API allows users to define… Go to article…
-
Categorical Foundations for CuTe Layouts

In GPU programming, performance depends critically on how data is stored and accessed in memory. While the data we care about is typically multi-dimensional, the GPU’s memory is fundamentally one-dimensional. This means that when we want to load, store, or otherwise manipulate data, we need to map its multi-dimensional logical coordinates to one-dimensional physical coordinates. This mapping, known as a… Go to article…
-
CUTLASS 3.x APIs: Orthogonal, Reusable, and Composable Abstractions for GEMM Kernel Design (External)
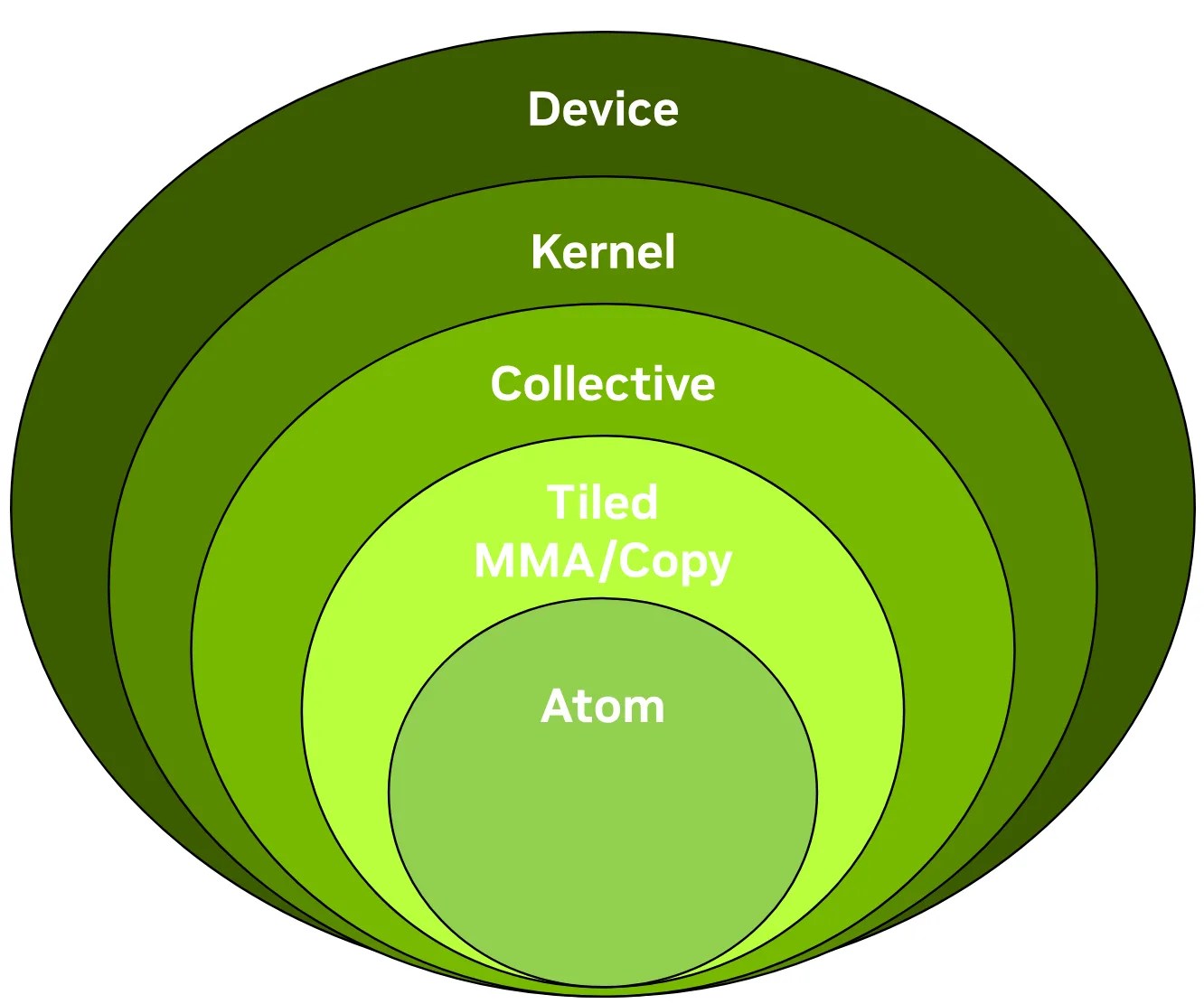
In this blog post presented on the NVIDIA technical blog, we give a concise introduction to the CUTLASS 3.x APIs, focusing on the collective, kernel, and device layers and the functionality of the collective builders. This post was authored in conjunction with members of the CUTLASS team. Go to article…
-
CUTLASS Tutorial: Sub-byte GEMM on NVIDIA® Blackwell GPUs

Welcome to part 3 of our series investigating GEMM on the NVIDIA Blackwell architecture. In parts 1 and 2, we looked at the Tensory Memory and 2 SM capabilities of the new Blackwell Tensor Core UMMA instructions and how to work with them in CUTLASS. In this part, we introduce low-precision computation and then discuss how it is carried out… Go to article…
-
CUTLASS Tutorial: GEMM with Thread Block Clusters on NVIDIA® Blackwell GPUs

Welcome to part two of our series investigating GEMM on the NVIDIA Blackwell architecture. In part 1, we introduced some key new features available on NVIDIA Blackwell GPUs, including Tensor Memory, and went over how to write a simple CUTLASS GEMM kernel that uses the new UMMA instructions (tcgen05.mma) to target the Blackwell Tensor Cores. In this post, we will… Go to article…