Category: Article
-
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
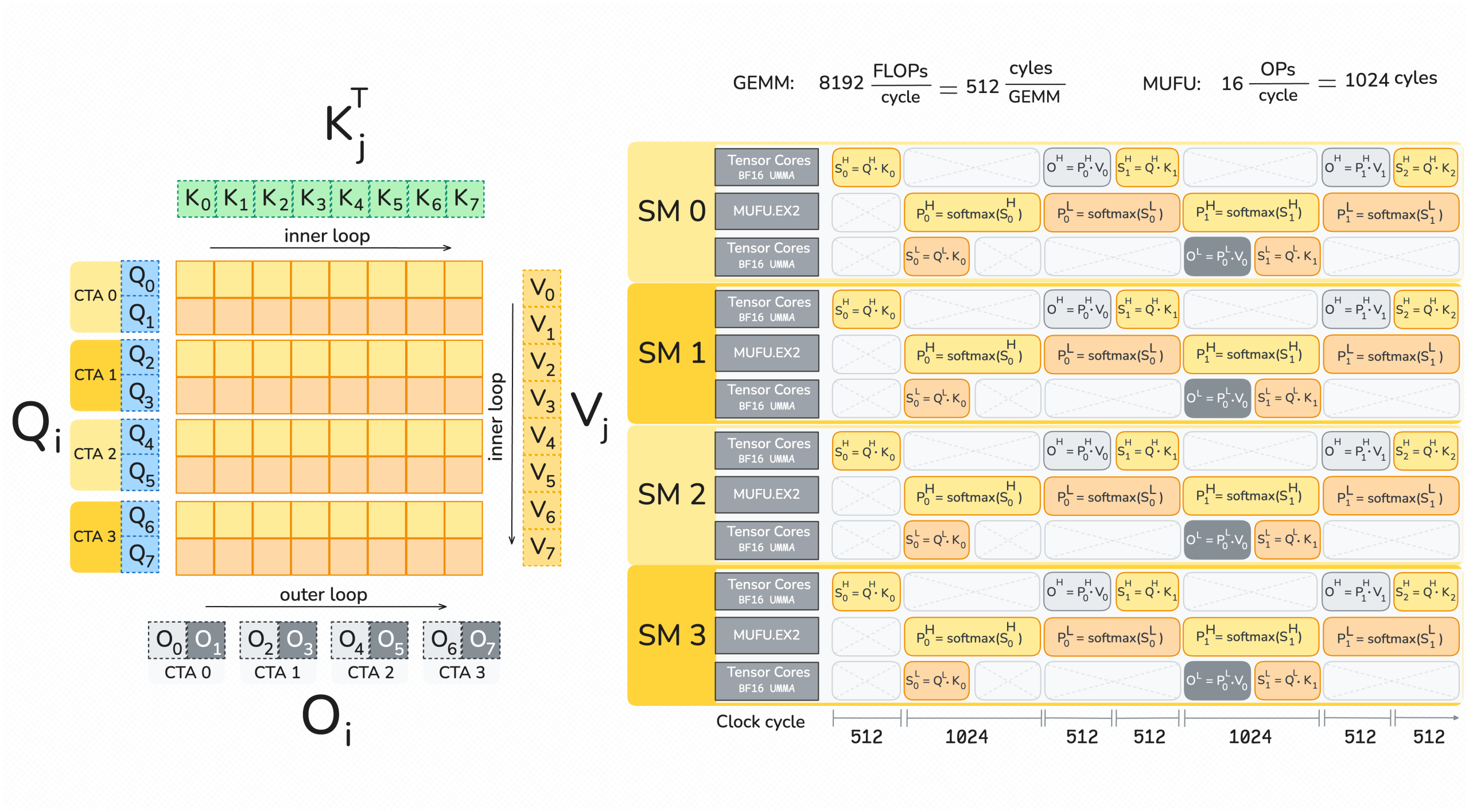
Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core… Go to article…
-
DeepSeek-R1 and FP8 Mixed-Precision Training
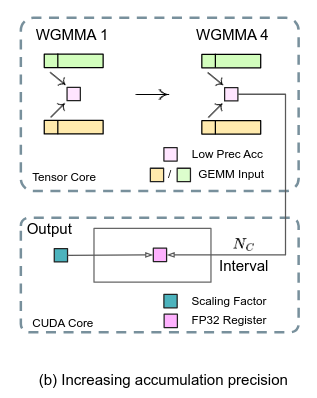
DeepSeek has shocked the world with the release of their reasoning model DeepSeek-R1. Similar to OpenAI’s o1 and Google Gemini’s Flash Thinking, the R1 model aims to improve the quality of its replies by generating a “chain of thought” before responding to a prompt. The excitement around R1 stems from it achieving parity with o1 Go to article…
-
CUTLASS Tutorial: Persistent Kernels and Stream-K
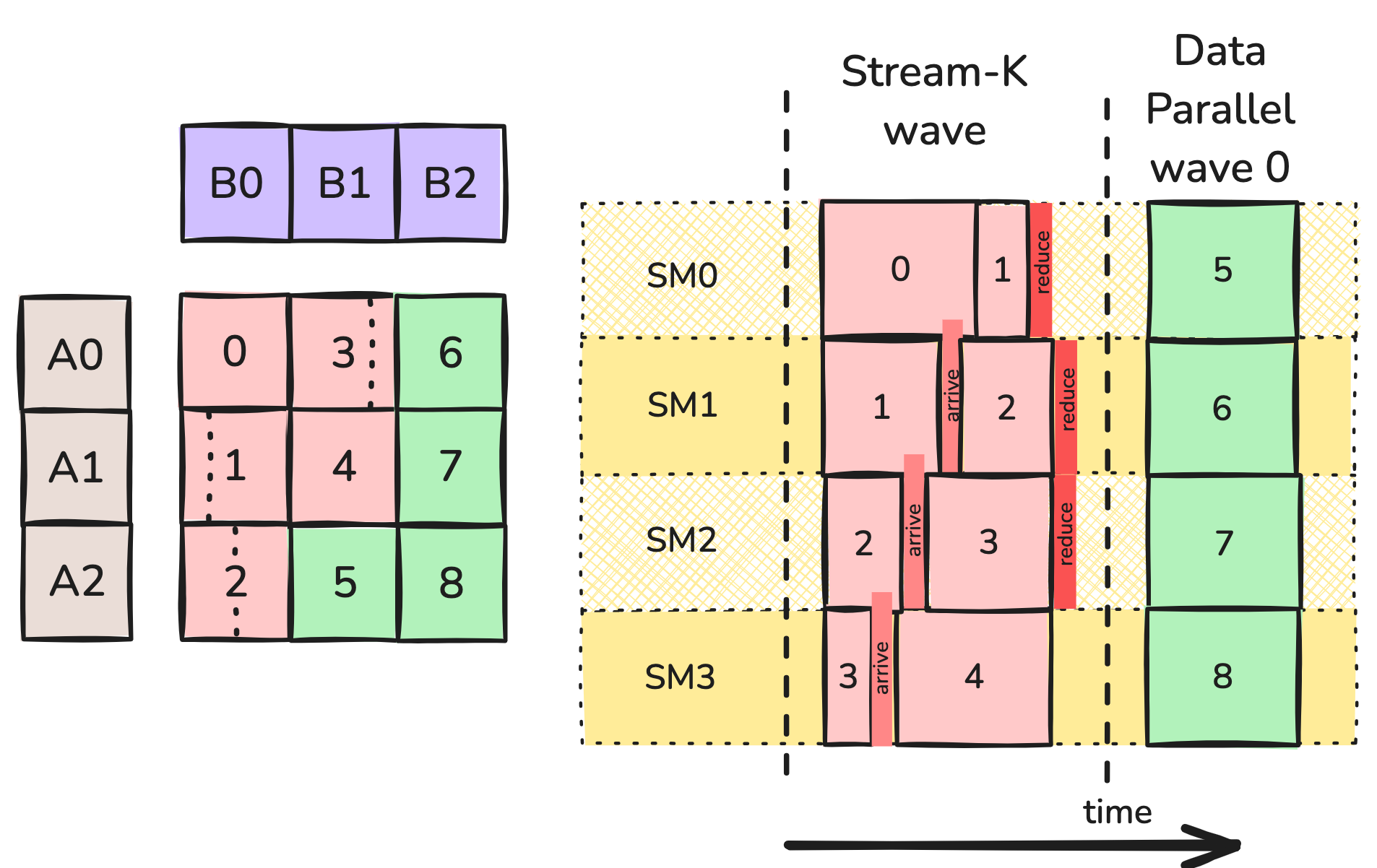
Welcome to Part 3 of our tutorial series on GEMM (GEneral Matrix Multiplication). In Parts 1 and 2, we discussed GEMM at length from the perspective of a single threadblock, introducing the WGMMA matmul primitive, pipelining, and warp specialization. In this part, we will examine GEMM from the perspective of the entire grid. At this Go to article…
-
Epilogue Fusion in CUTLASS with Epilogue Visitor Trees
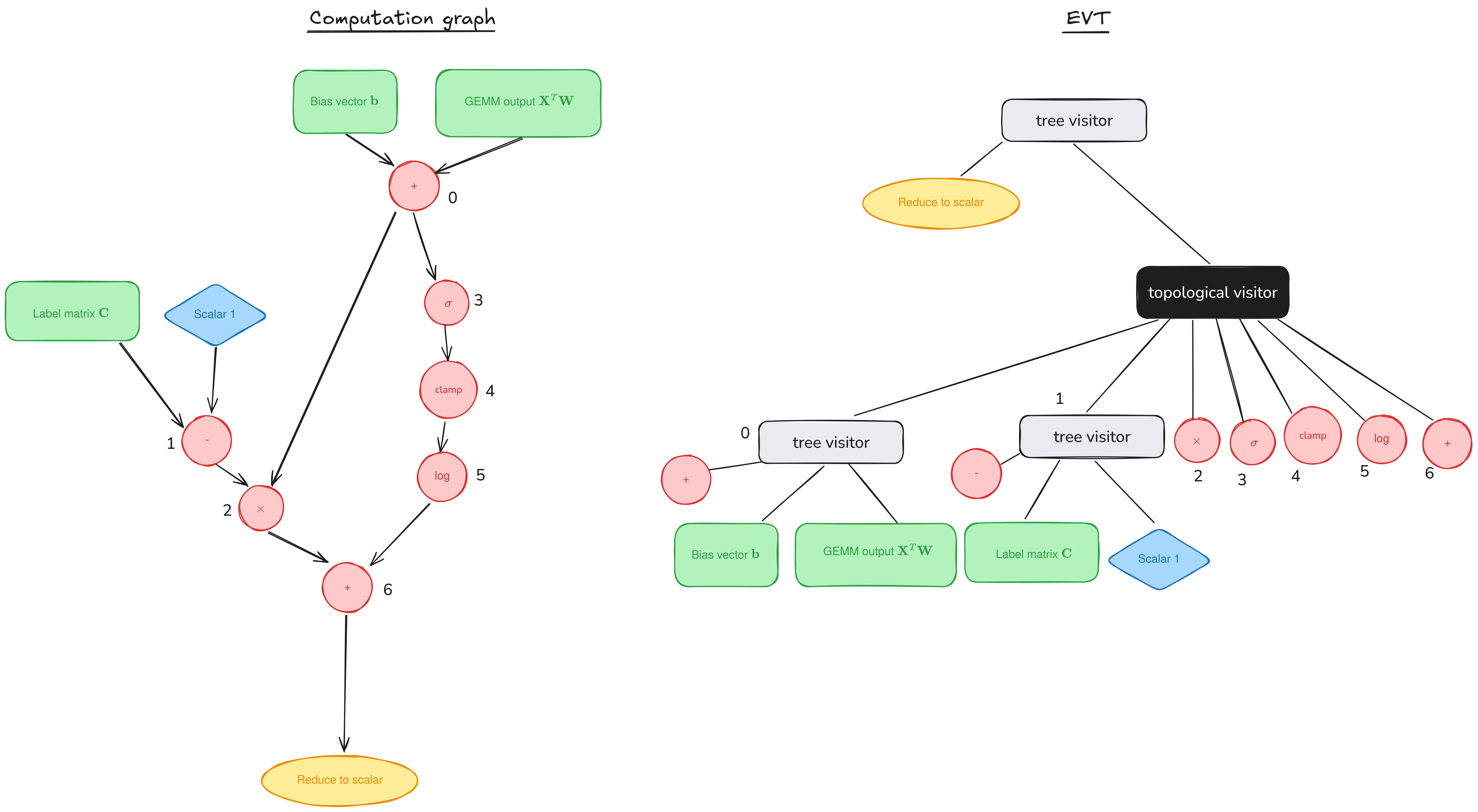
Welcome to a supplemental article for our tutorial series on GEMM (GEneral Matrix Multiplication). Posts in the main series (1, 2) have discussed performant implementations of GEMM on NVIDIA GPUs by looking at the mainloop, the part responsible for the actual GEMM computation. But the mainloop is only a part of the CUTLASS workload. In Go to article…
-
GPU passthrough on Proxmox VE 8.2
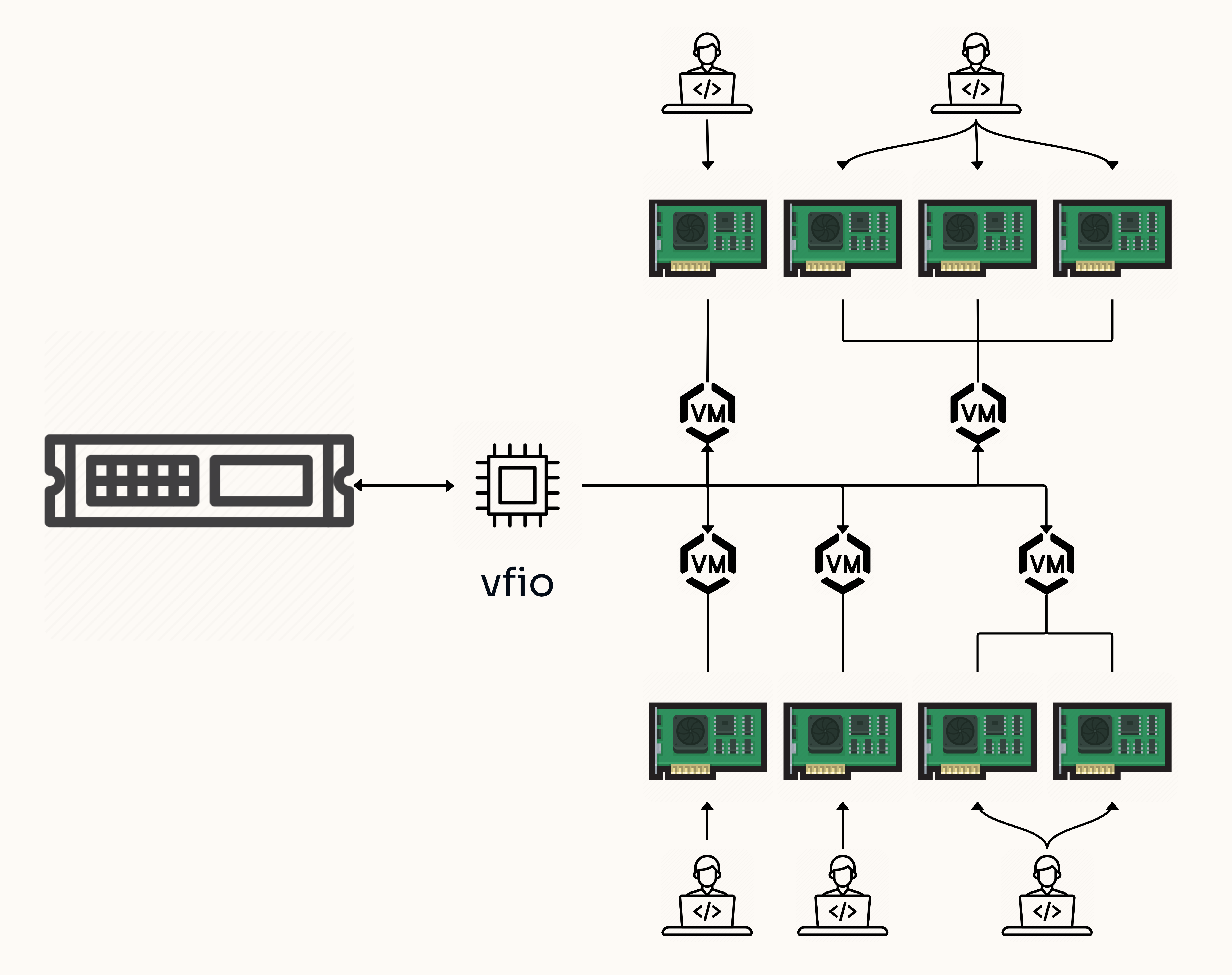
In this guide, we will walk through the steps to enable GPU passthrough and by extension PCIe passthrough on a virtual machine (VM) deployed through Proxmox. PCIe passthrough provides a path for VMs to directly access underlying PCIe hardware, in the case of this article, an Nvidia® A30 GPU. This setup is ideal for scenarios Go to article…
-
CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining
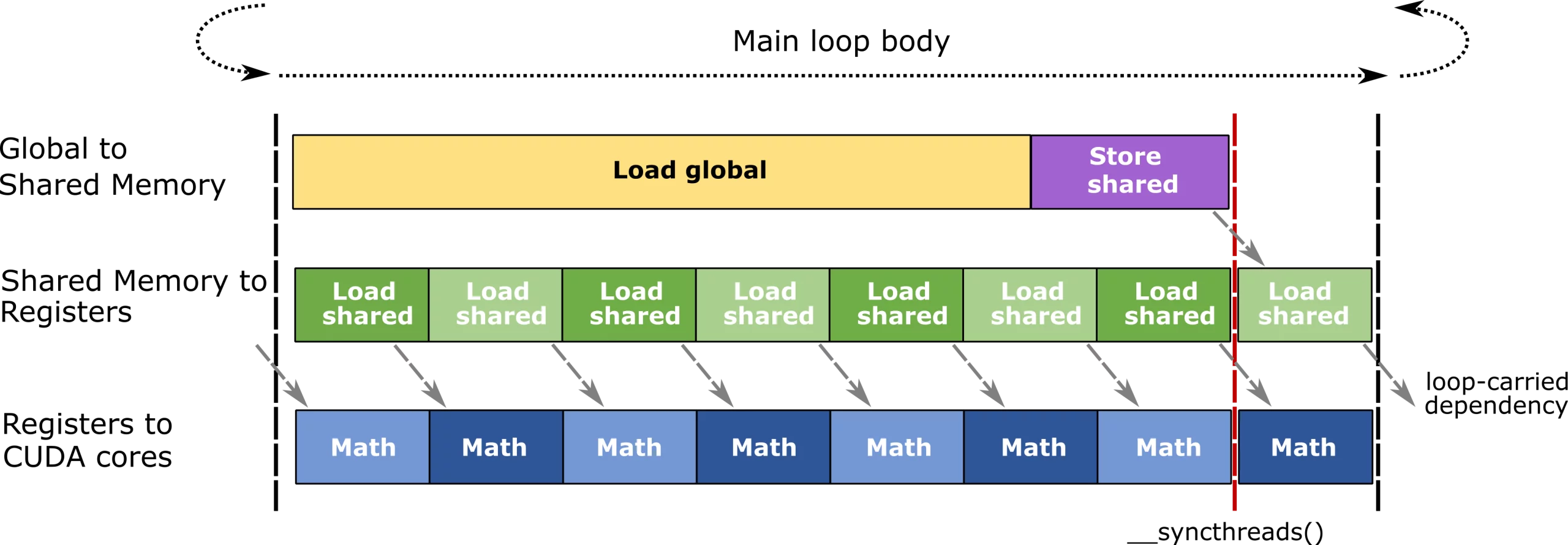
Welcome to Part 2 of our tutorial series on GEMM (GEneral Matrix Multiplication). In Part 1, we discussed the computational side of GEMM by going over WGMMA, which is the primitive instruction to multiply small matrix tiles on GPUs based on the NVIDIA® Hopper™ architecture. In this part, we turn our focus to the memory Go to article…
-
CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs
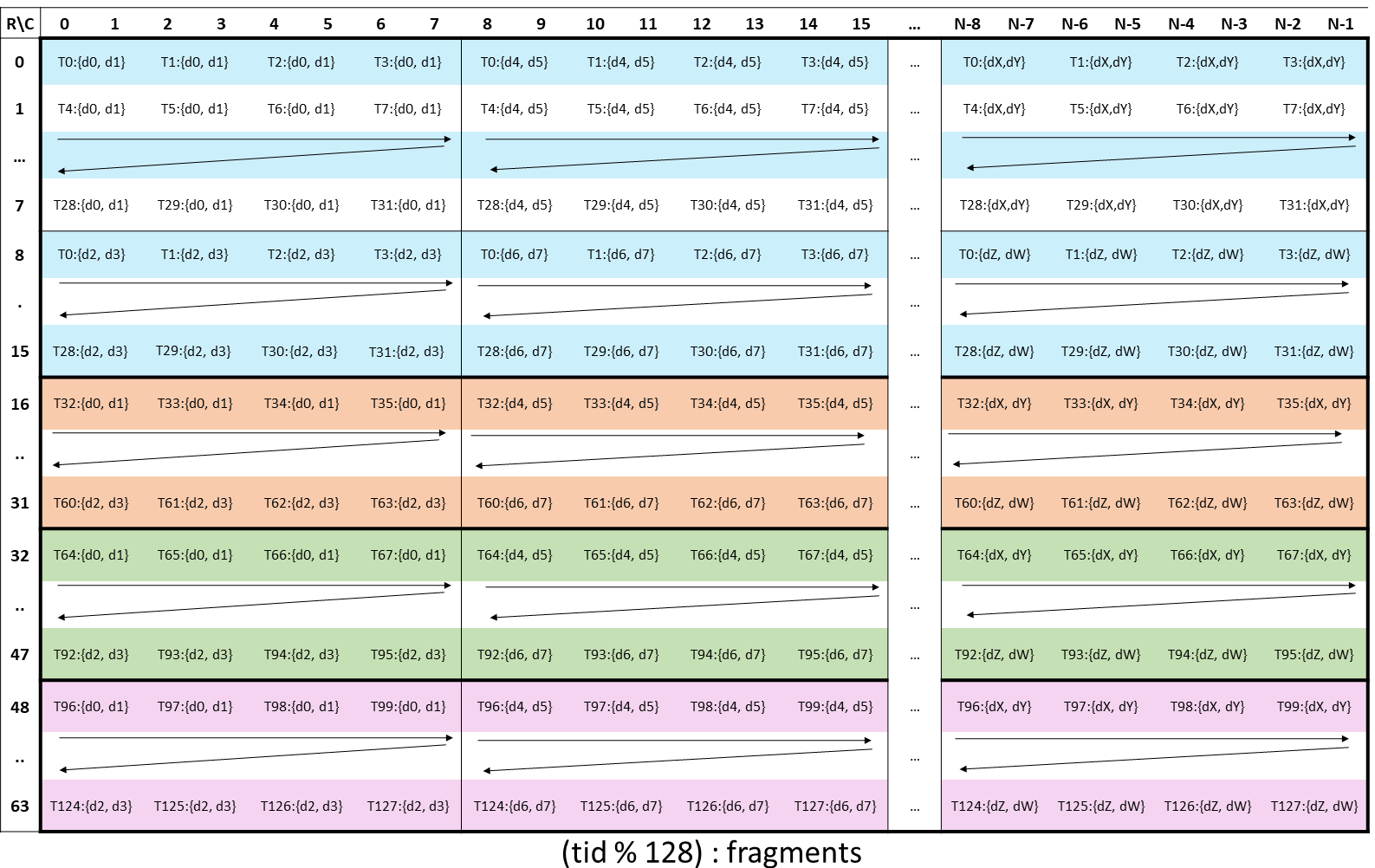
No series of CUDA® tutorials is complete without a section on GEMM (GEneral Matrix Multiplication). Arguably the most important routine on modern GPUs, GEMM constitutes the majority of compute done in neural networks, large language models, and many graphics applications. Despite its ubiquity, GEMM is notoriously hard to implement efficiently. This 3-part tutorial series aims Go to article…
-
CUTLASS Tutorial: Mastering the NVIDIA® Tensor Memory Accelerator (TMA)
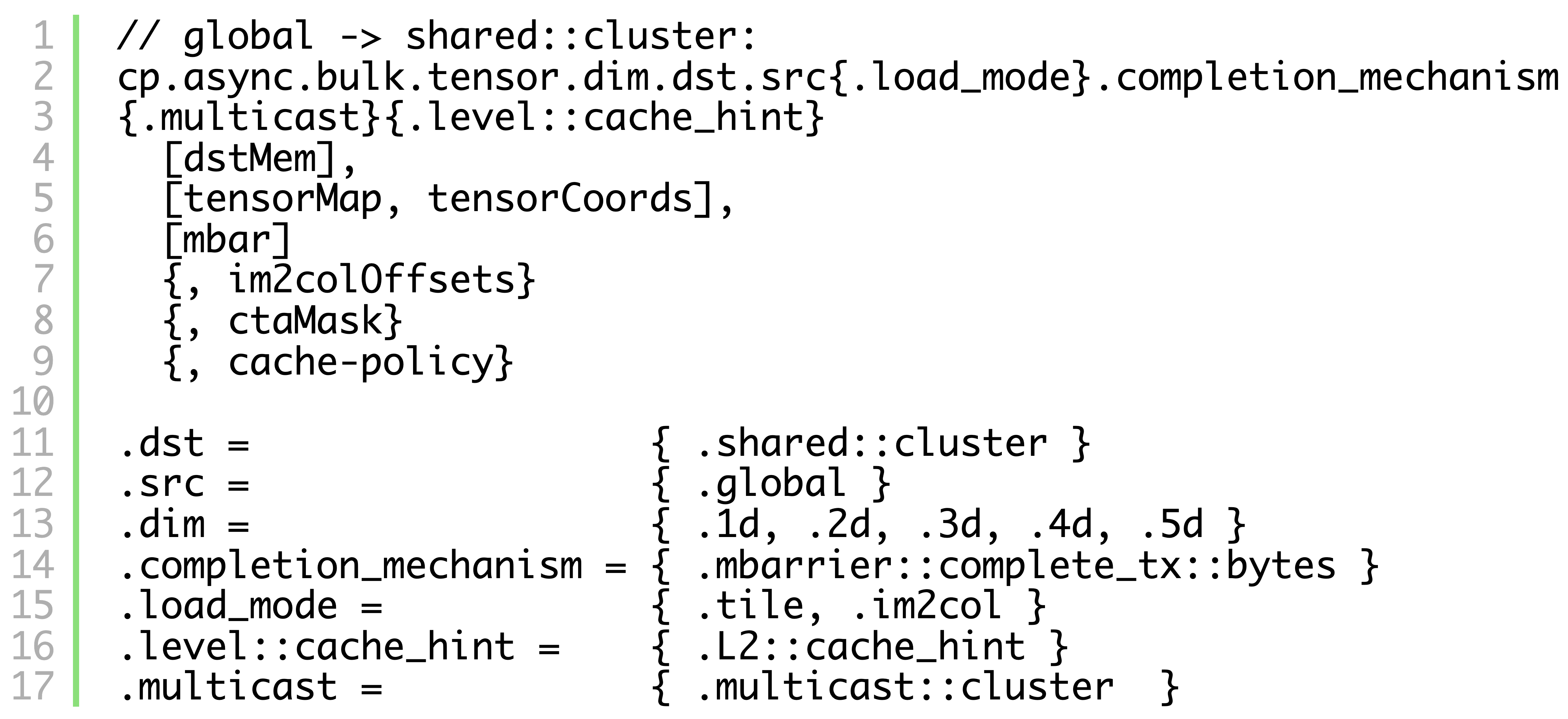
TMA (Tensor Memory Accelerator) is a new feature introduced in the NVIDIA Hopper™ architecture for doing asynchronous memory copy between a GPU’s global memory (GMEM) and the shared memory (SMEM) of its threadblocks (i.e., CTAs). Compared to prior approaches, TMA offers a number of advantages, such as (1) improving GPU utilization through facilitating warp-specialized kernel Go to article…
-
Sharing NVIDIA® GPUs at the System Level: Time-Sliced and MIG-Backed vGPUs
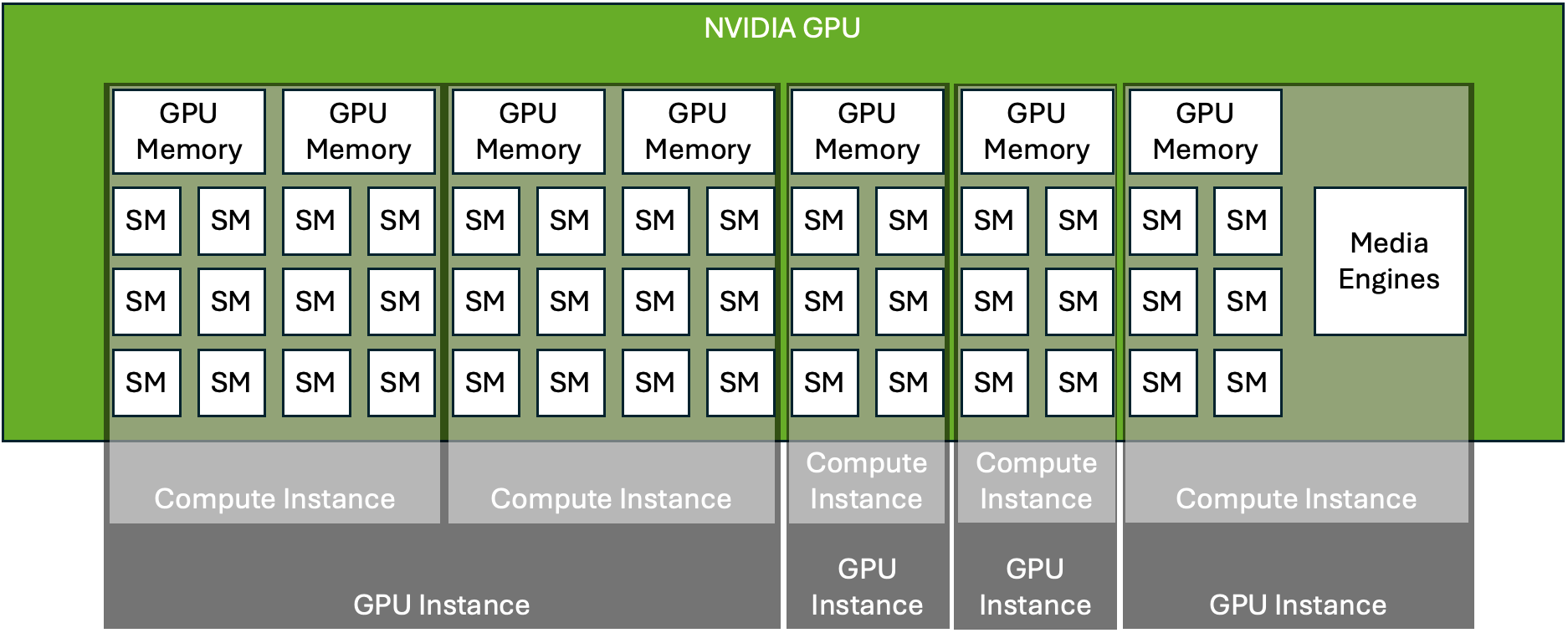
While some modern applications for GPUs aim to consume all GPU resources and even scale to multiple GPUs (deep learning training, for instance), other applications require only a fraction of GPU resources (like some deep learning inferencing) or don’t use GPUs all the time (for example, a developer working on an NVIDIA CUDA® application may Go to article…
-
Tutorial: Matrix Transpose in CUTLASS
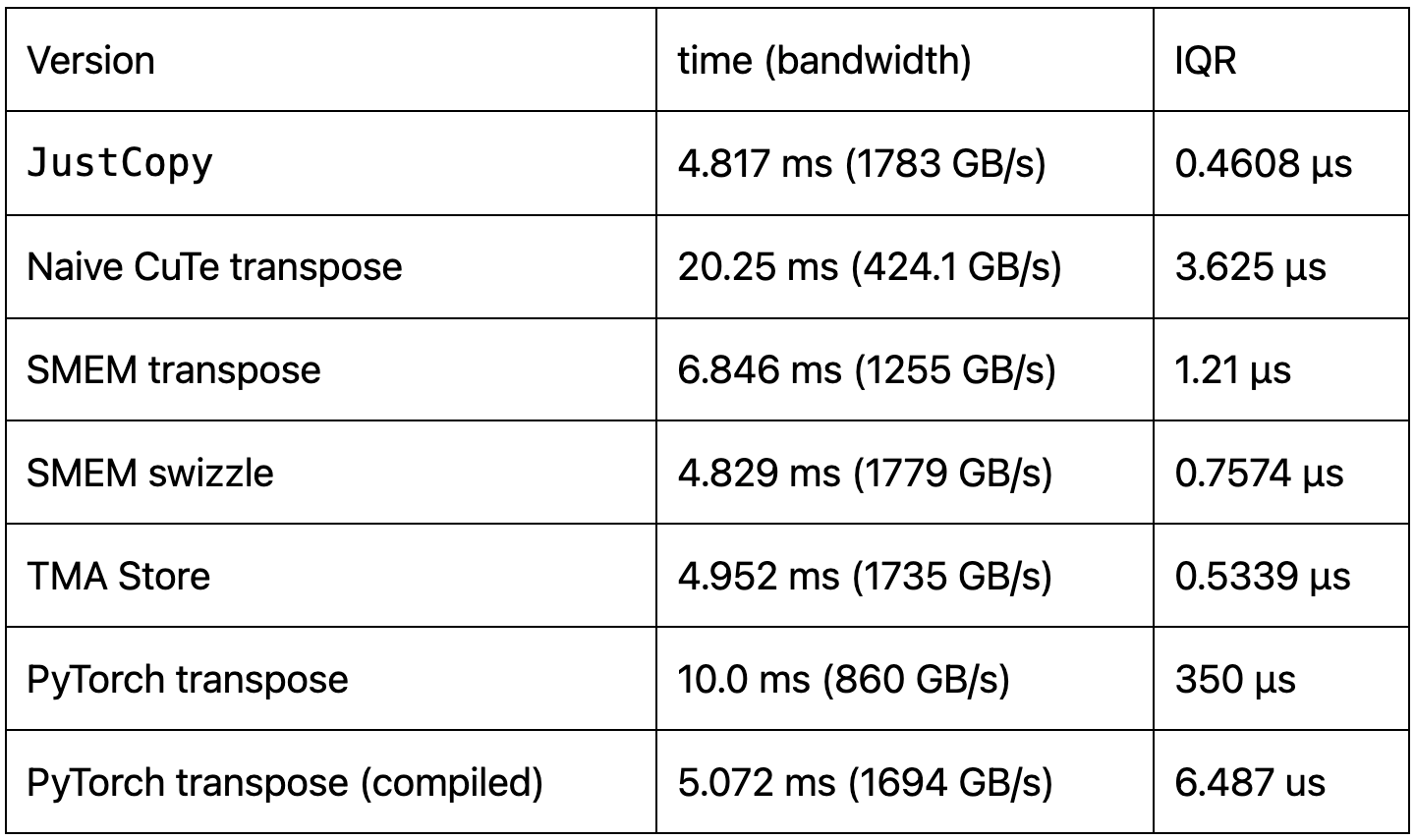
The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will study the task of matrix transpose as an illustrative example for these concepts. We choose this task because it involves no operation other than Go to article…