Category: Publications
-
Dynamic persistent tile scheduling with Cluster Launch Control (CLC) on NVIDIA Blackwell GPUs
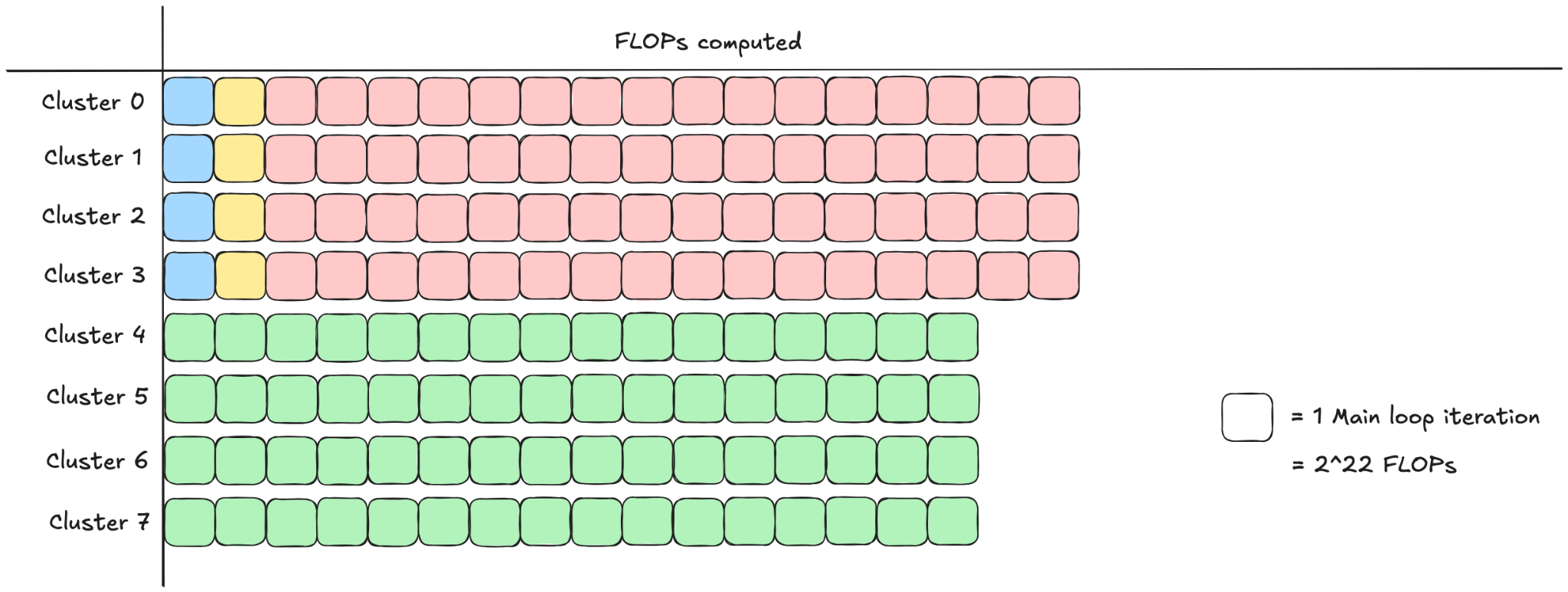
This blog post discusses Cluster Launch Control (CLC), a hardware-supported feature on NVIDIA Blackwell GPUs that facilitates optimal tile scheduling, in particular with respect to load balancing. To provide context, we first survey a few common scheduling strategies and the deficiencies CLC is designed to address. We then walk through the implementation-level details of using… Go to article…
-
GPU Mode: Fundamentals of CuTe Layout Algebra and Category-Theoretic Interpretation
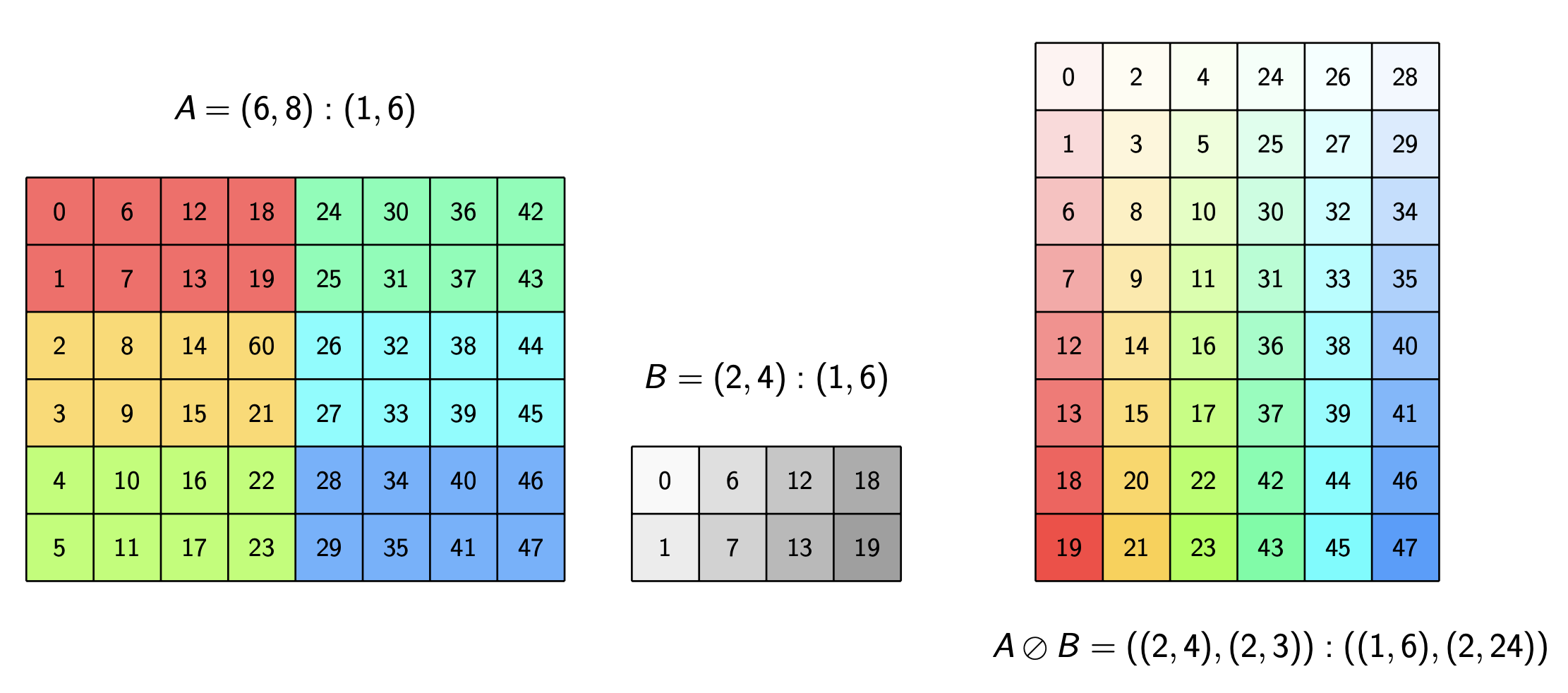
In this GPU Mode lecture, Jack Carlisle reviews the fundamental concepts of CuTe layout algebra and then presents our category-theoretic mathematical framework for understanding layouts and their algebraic structure. Go to article…
-
FlexAttention + FlashAttention-4: Fast and Flexible (External)

In this PyTorch blog on which we collaborated, we explain the FlexAttention extension to FlashAttention-4 (or from another point of view, the incorporation of FA-4 as an attention backend for the PyTorch FlexAttention API). Go to article…
-
CUTLASS Tutorial: Hardware-supported Block-scaling with NVIDIA Blackwell GPUs

Welcome to part 4 of our series investigating GEMM on the NVIDIA Blackwell architecture. So far we have discussed the capabilities of the new Blackwell Tensor Core UMMA instructions, including handling sub-byte data types, and how to work with them in CUTLASS. In this part, we will continue our exploration of low-precision computation by discussing… Go to article…
-
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
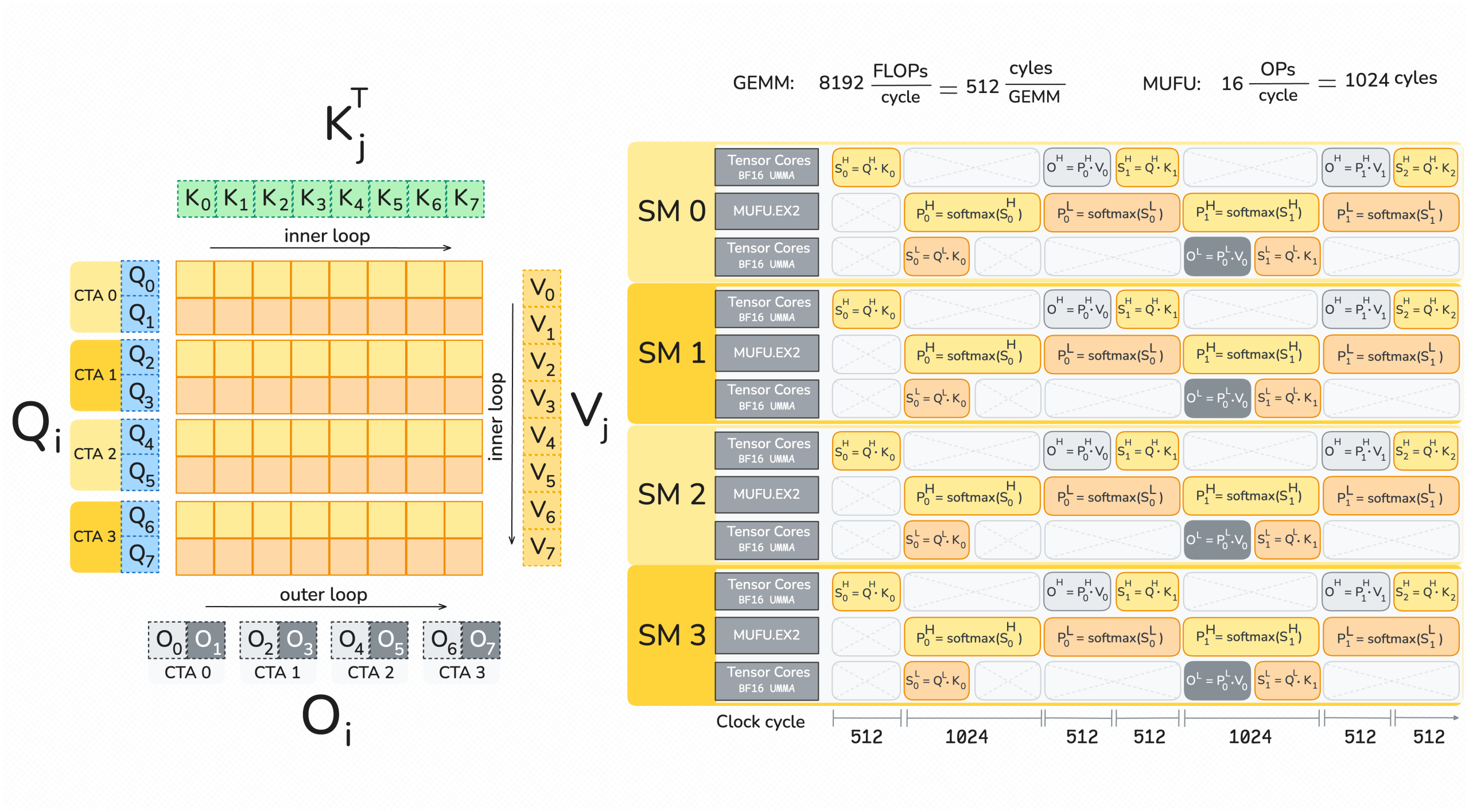
Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core… Go to article…
-
A User’s Guide to FlexAttention in FlashAttention CuTe DSL

Many variants of attention (Vaswani et al., 2017) have become popular in recent years, for reasons related to performance and model quality. These include: The PyTorch team at Meta recognized that most of these variants (including all of the above) can be unified under one elegant framework, dubbed FlexAttention (Guessous et al., 2024). This simple… Go to article…
-
Categorical Foundations for CuTe Layouts
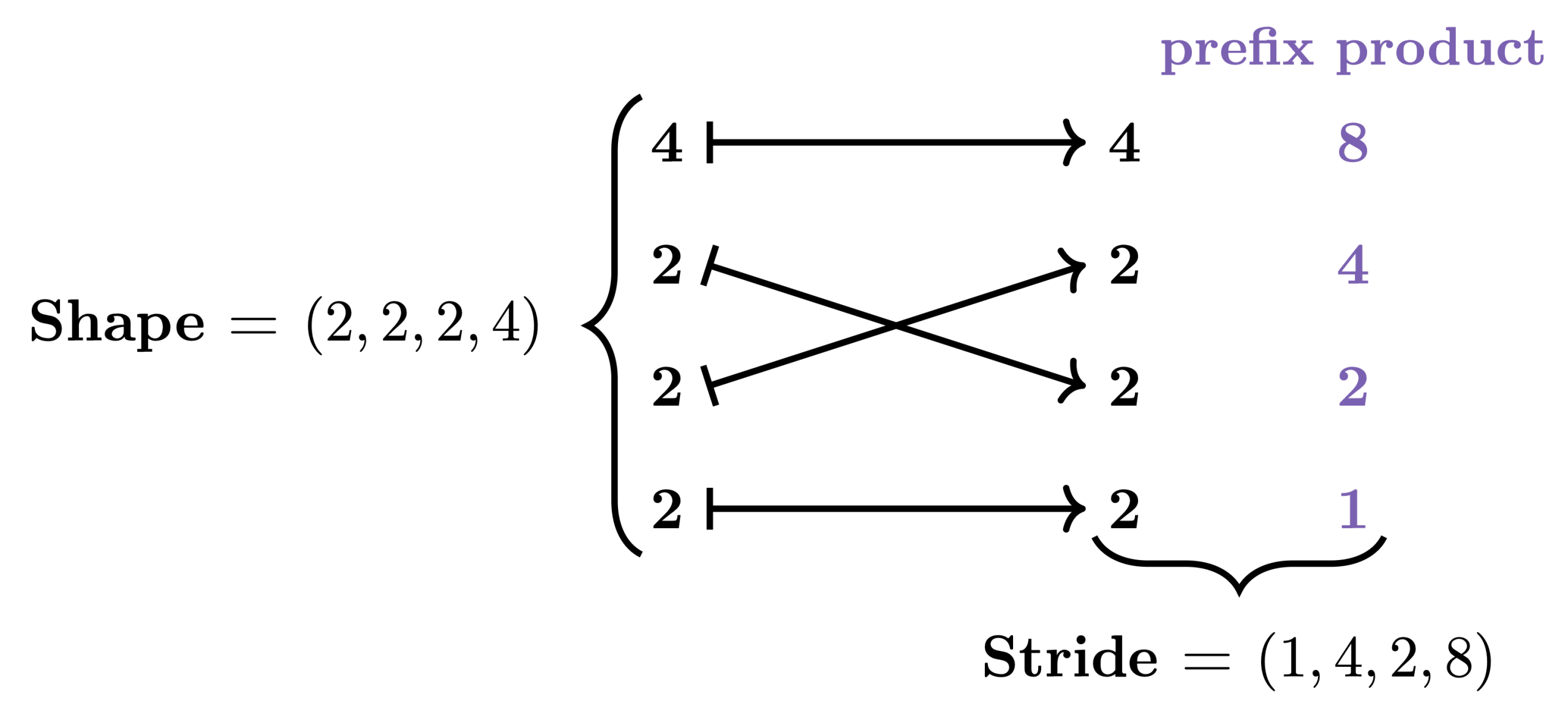
In GPU programming, performance depends critically on how data is stored and accessed in memory. While the data we care about is typically multi-dimensional, the GPU’s memory is fundamentally one-dimensional. This means that when we want to load, store, or otherwise manipulate data, we need to map its multi-dimensional logical coordinates to one-dimensional physical coordinates.… Go to article…
-
CUTLASS Tutorial: Sub-byte GEMM on NVIDIA® Blackwell GPUs
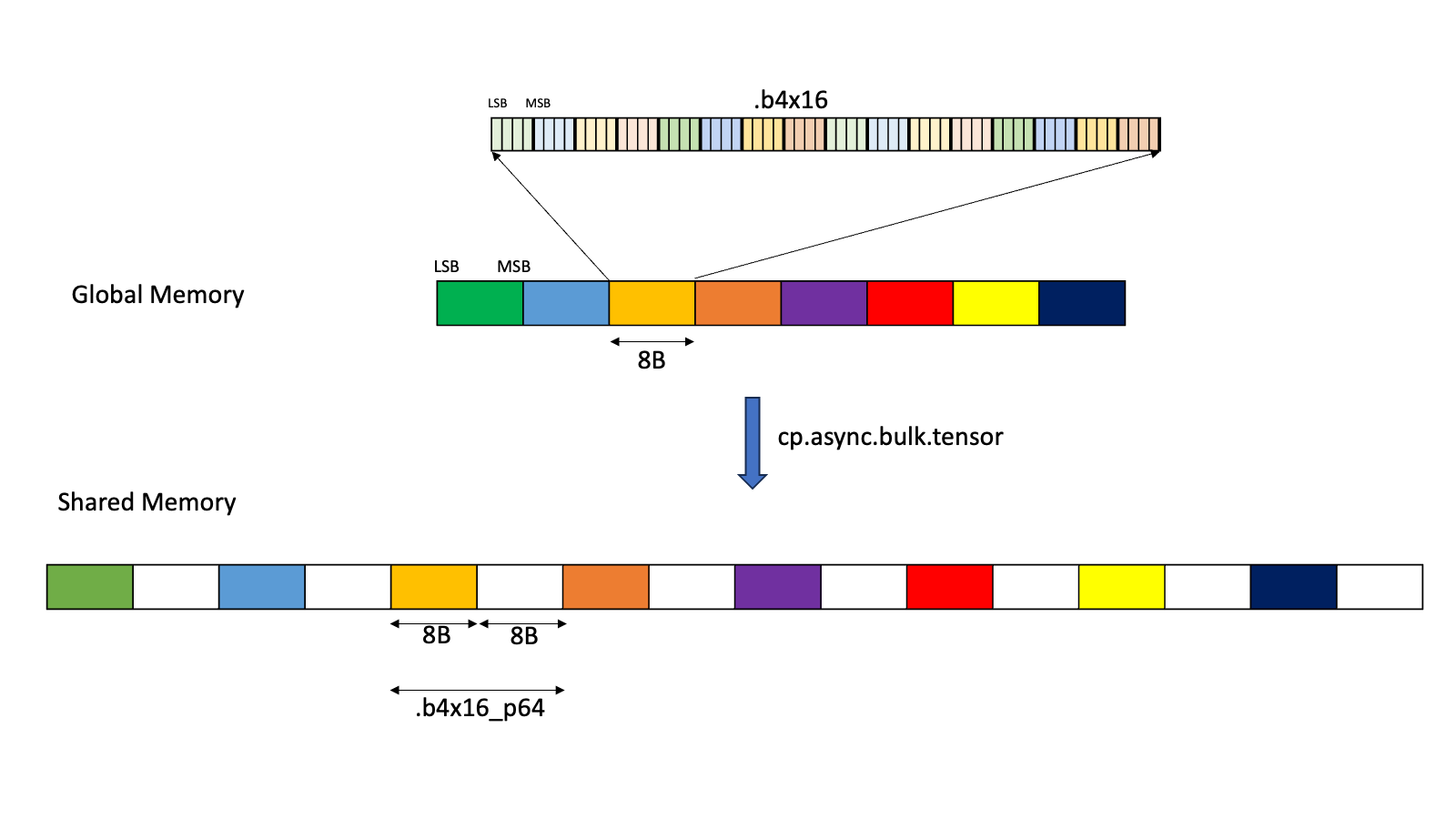
Welcome to part 3 of our series investigating GEMM on the NVIDIA Blackwell architecture. In parts 1 and 2, we looked at the Tensory Memory and 2 SM capabilities of the new Blackwell Tensor Core UMMA instructions and how to work with them in CUTLASS. In this part, we introduce low-precision computation and then discuss… Go to article…
-
CUTLASS Tutorial: GEMM with Thread Block Clusters on NVIDIA® Blackwell GPUs
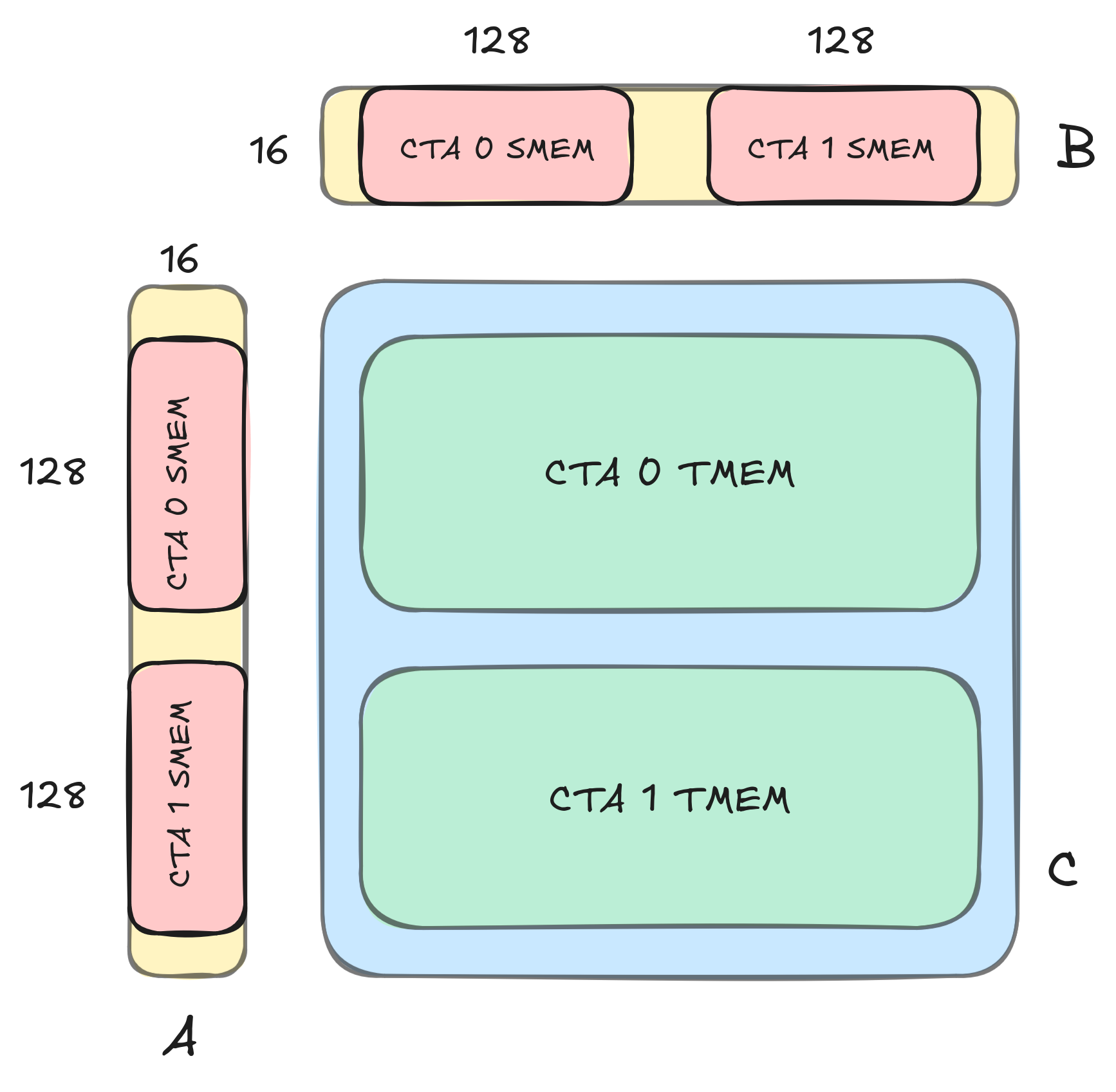
Welcome to part two of our series investigating GEMM on the NVIDIA Blackwell architecture. In part 1, we introduced some key new features available on NVIDIA Blackwell GPUs, including Tensor Memory, and went over how to write a simple CUTLASS GEMM kernel that uses the new UMMA instructions (tcgen05.mma) to target the Blackwell Tensor Cores.… Go to article…
-
CUTLASS Tutorial: Writing GEMM Kernels Using Tensor Memory For NVIDIA® Blackwell GPUs
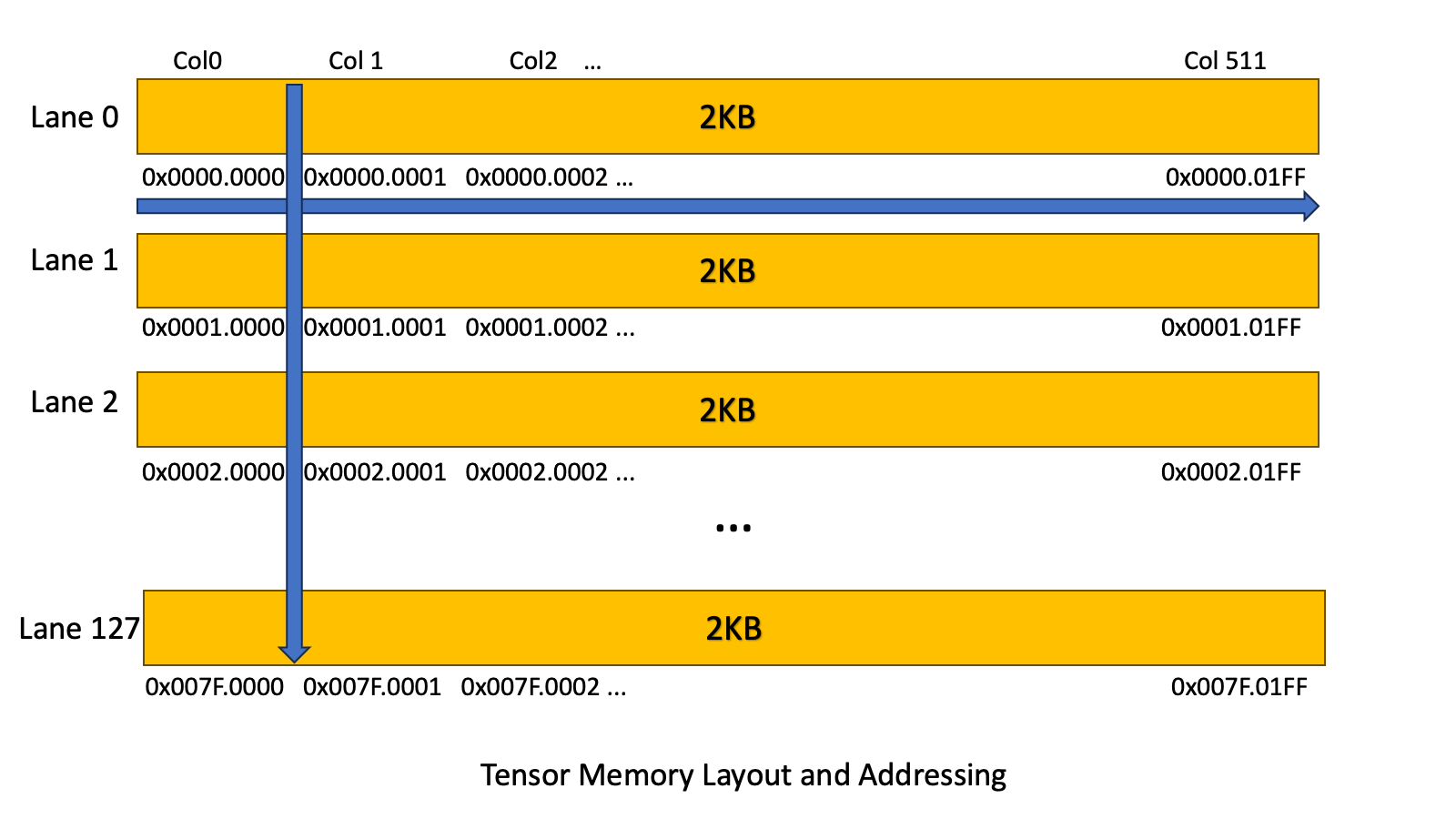
The NVIDIA Blackwell architecture introduces some new features that significantly change the shape of a GEMM kernel. In this series of posts, we explore the new features available on Blackwell and examine how to write CUTLASS GEMM kernels that utilize these new features by drawing on the CuTe tutorial examples. The goal of this series… Go to article…