Category: Benchmarks
-
FlashAttention-3 for Inference: INT8 Quantization and Query Head Packing for MQA/GQA (External)

In this blog post presented on the Character.AI research blog, we explain two techniques that are important for using FlashAttention-3 for inference: in-kernel pre-processing of tensors via warp specialization and query head packing for MQA/GQA. Go to article…
-
Sharing NVIDIA® GPUs at the System Level: Time-Sliced and MIG-Backed vGPUs
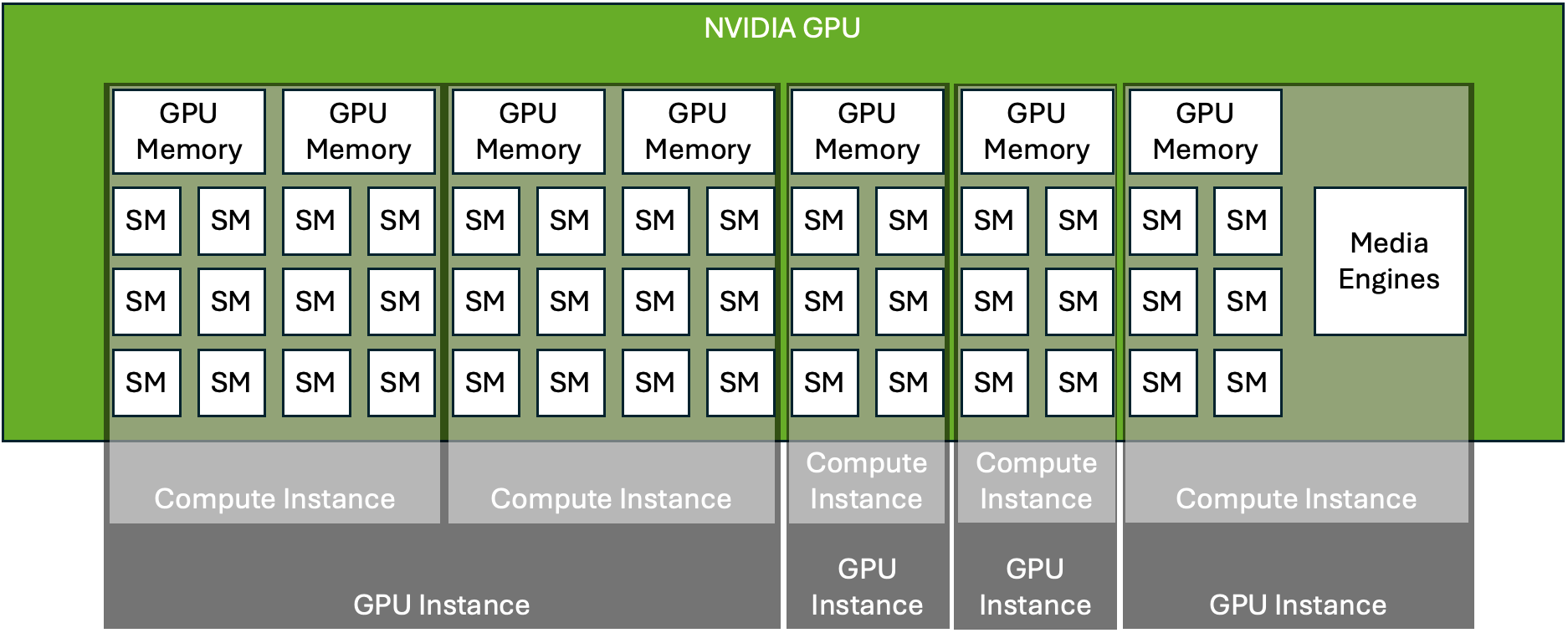
While some modern applications for GPUs aim to consume all GPU resources and even scale to multiple GPUs (deep learning training, for instance), other applications require only a fraction of GPU resources (like some deep learning inferencing) or don’t use GPUs all the time (for example, a developer working on an NVIDIA CUDA® application may Go to article…