Category: Deep Learning
-
GPU Mode: Fundamentals of CuTe Layout Algebra and Category-Theoretic Interpretation
In this GPU Mode lecture, Jack Carlisle reviews the fundamental concepts of CuTe layout algebra and then presents our category-theoretic mathematical framework for understanding layouts and their algebraic structure. Go to article…
-
FlexAttention + FlashAttention-4: Fast and Flexible (External)

In this PyTorch blog on which we collaborated, we explain the FlexAttention extension to FlashAttention-4 (or from another point of view, the incorporation of FA-4 as an attention backend for the PyTorch FlexAttention API). Go to article…
-
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
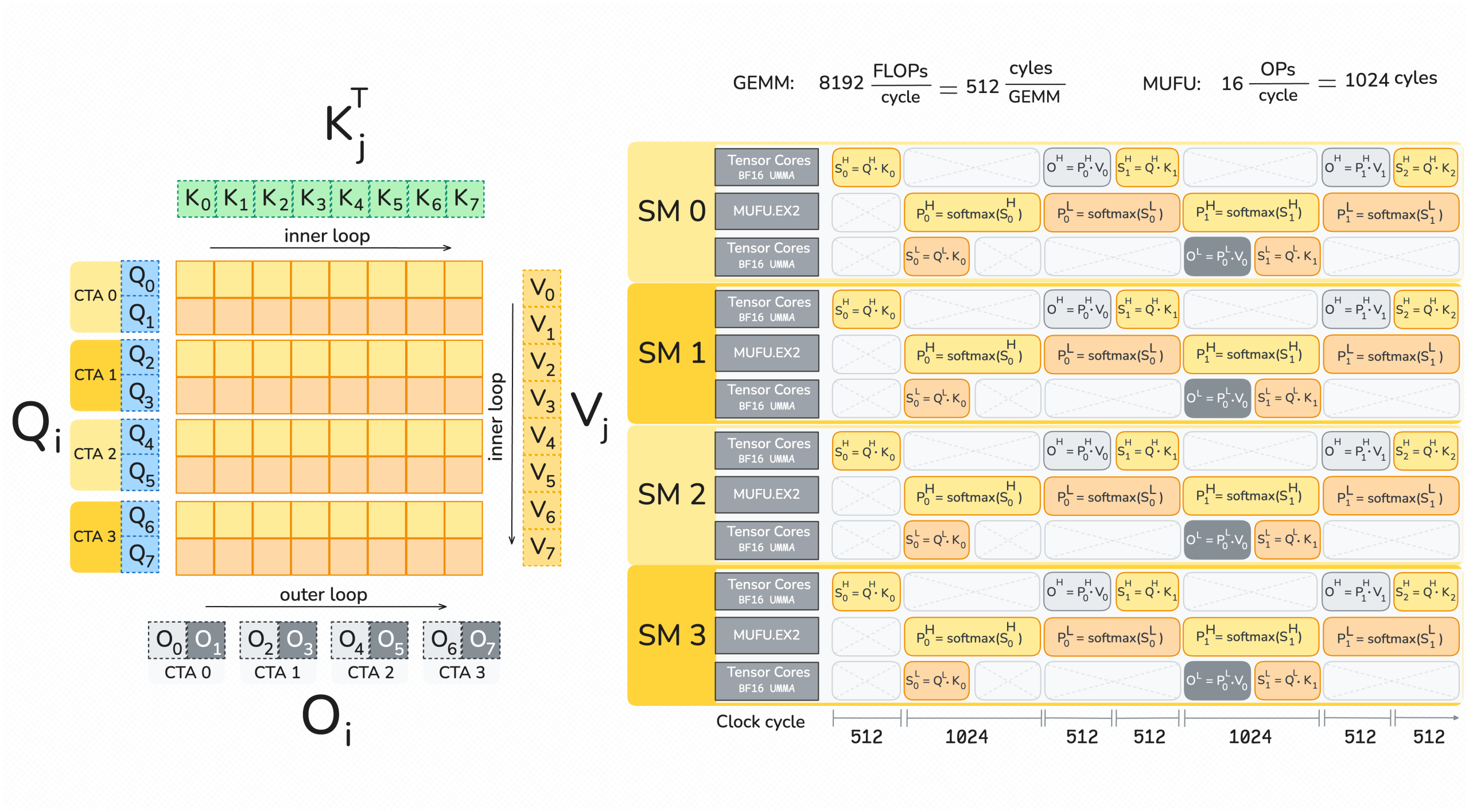
Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core… Go to article…
-
FlashAttention-3 for Inference: INT8 Quantization and Query Head Packing for MQA/GQA (External)

In this blog post presented on the Character.AI research blog, we explain two techniques that are important for using FlashAttention-3 for inference: in-kernel pre-processing of tensors via warp specialization and query head packing for MQA/GQA. Go to article…
-
GPU Mode: CUTLASS and FlashAttention-3
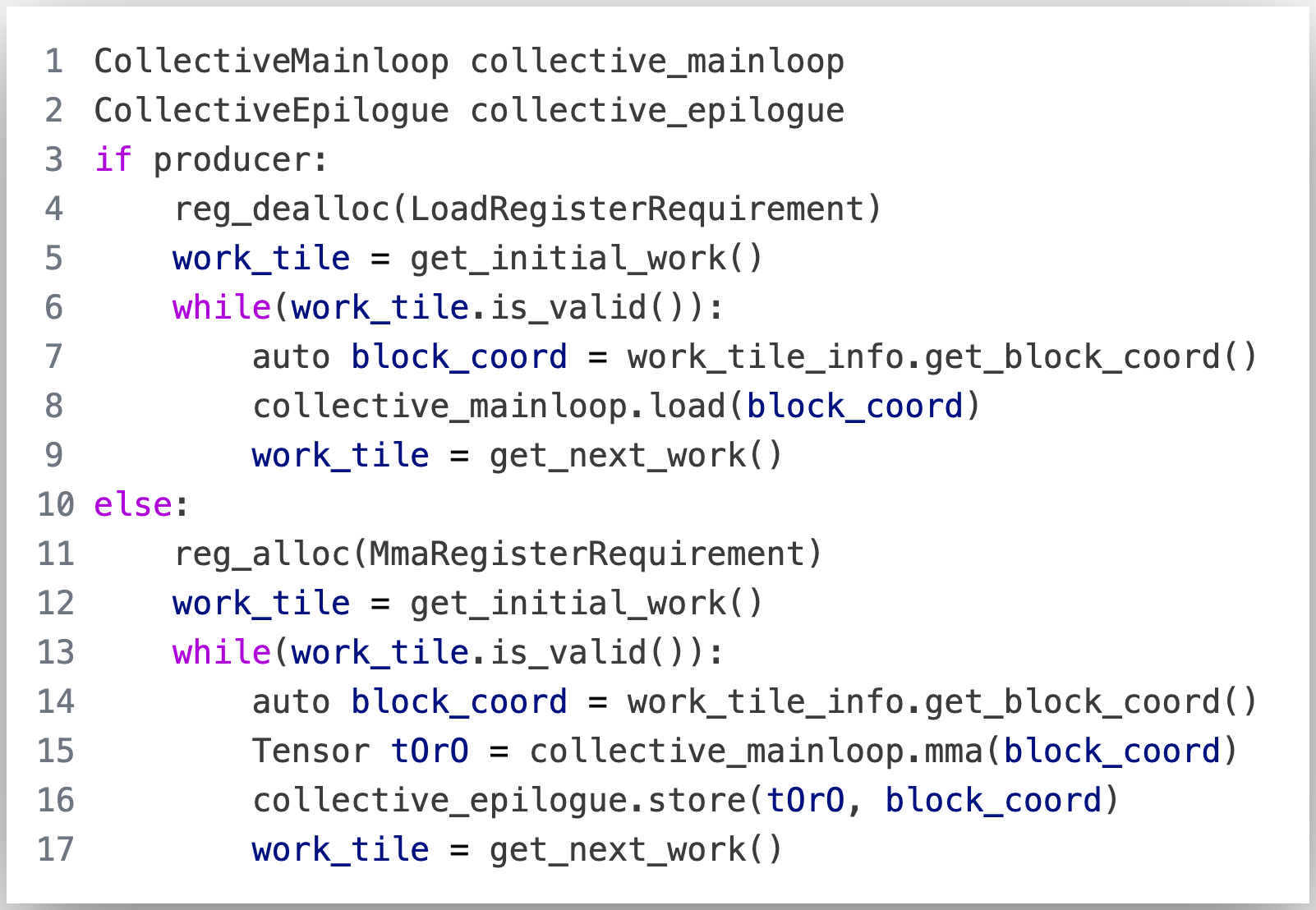
In this GPU Mode lecture, Jay Shah presents his joint work on FlashAttention-3 and how to implement the main compute loop in the algorithm using CUTLASS. The code discussed in this lecture can be found at this commit in the FlashAttention-3 codebase. Note: Slides adapted from a talk given by Tri Dao. Go to article…
-
Epilogue Fusion in CUTLASS with Epilogue Visitor Trees
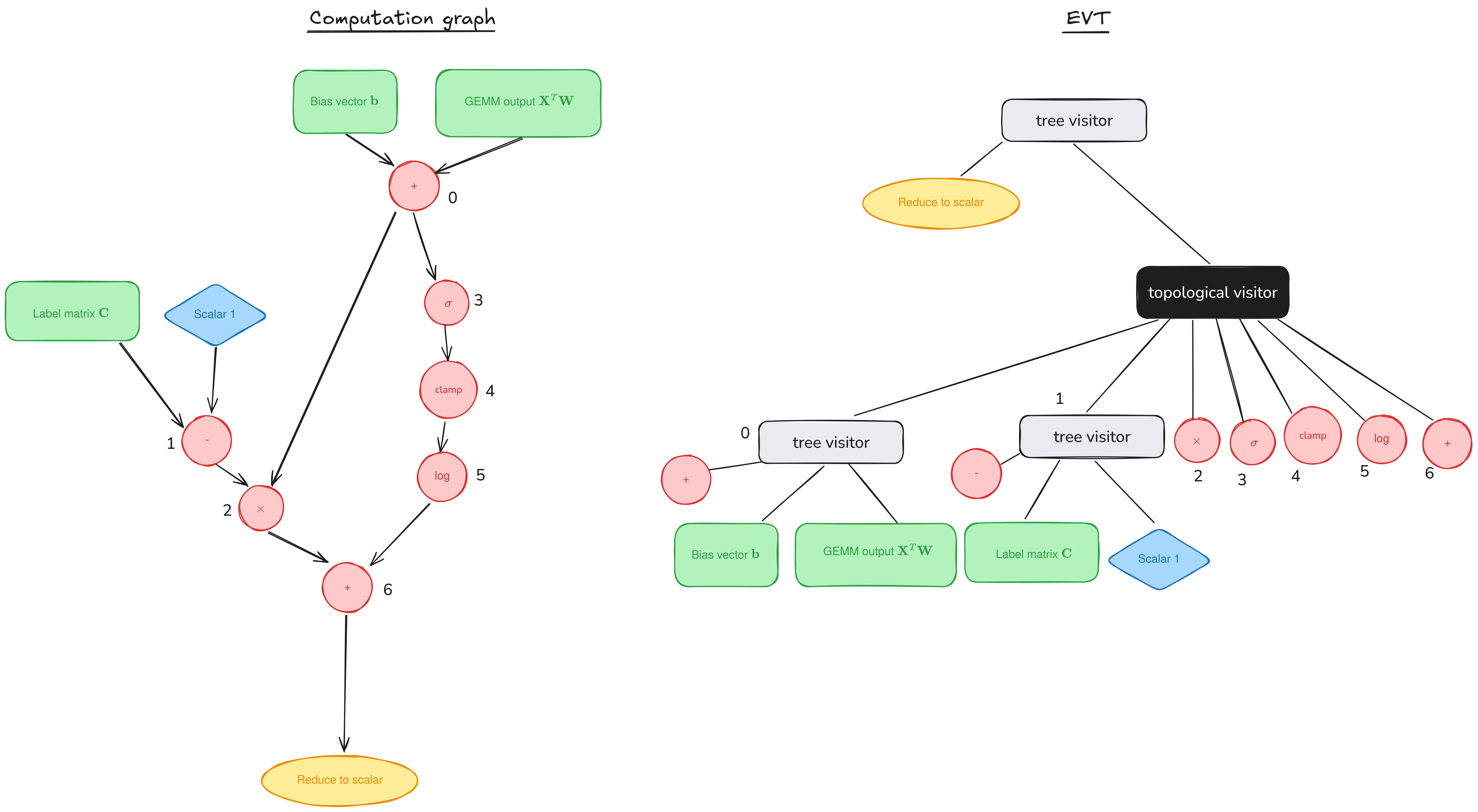
Welcome to a supplemental article for our tutorial series on GEMM (GEneral Matrix Multiplication). Posts in the main series (1, 2) have discussed performant implementations of GEMM on NVIDIA GPUs by looking at the mainloop, the part responsible for the actual GEMM computation. But the mainloop is only a part of the CUTLASS workload. In… Go to article…
-
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
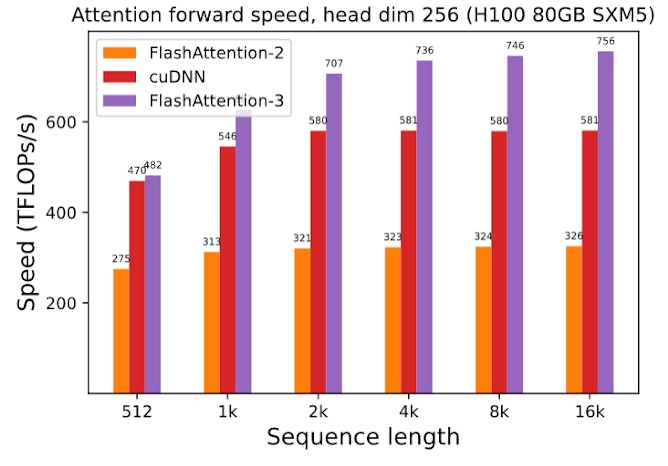
In this blogpost, we describe three main techniques that we use to speed up attention on Hopper GPUs in FlashAttention-3: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) incoherent processing that leverages hardware support for… Go to article…
-
Delivering 1 PFLOP/s of Performance with FP8 FlashAttention-2
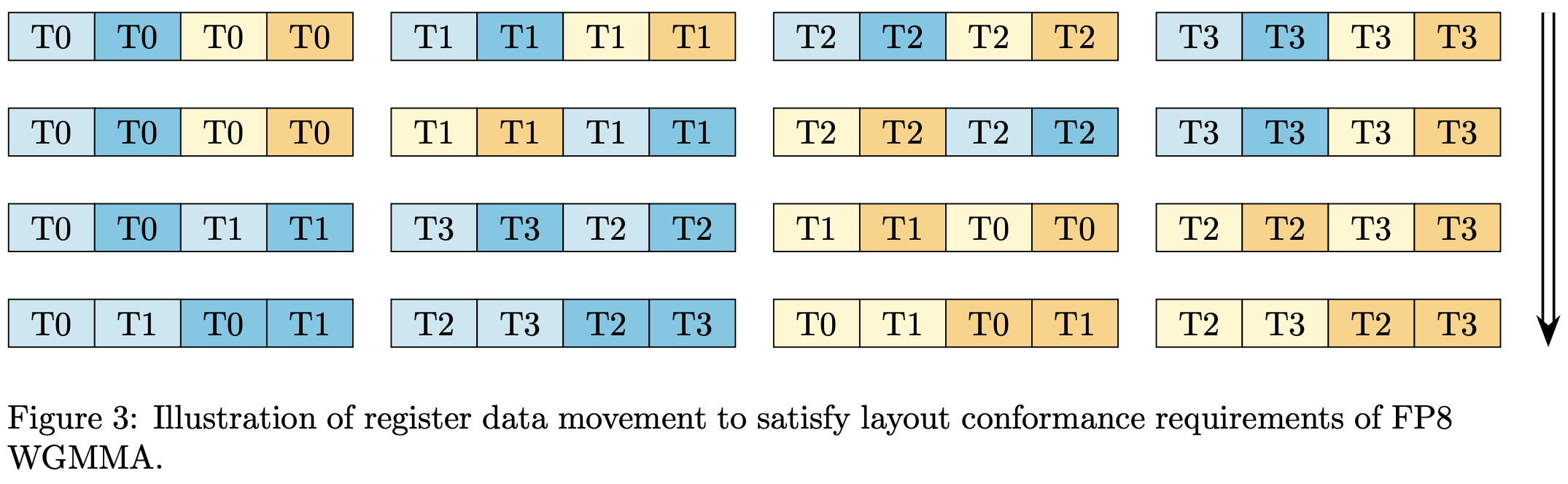
We recently released an update to our FlashAttention-2 forward pass implementation on NVIDIA Hopper™ architecture that incorporates a number of new optimizations and improvements, including a software pipelining scheme and FP8 support. In this article, we will explain a challenge with achieving layout conformance of register fragments for WGMMA instructions that we encountered in the… Go to article…
-
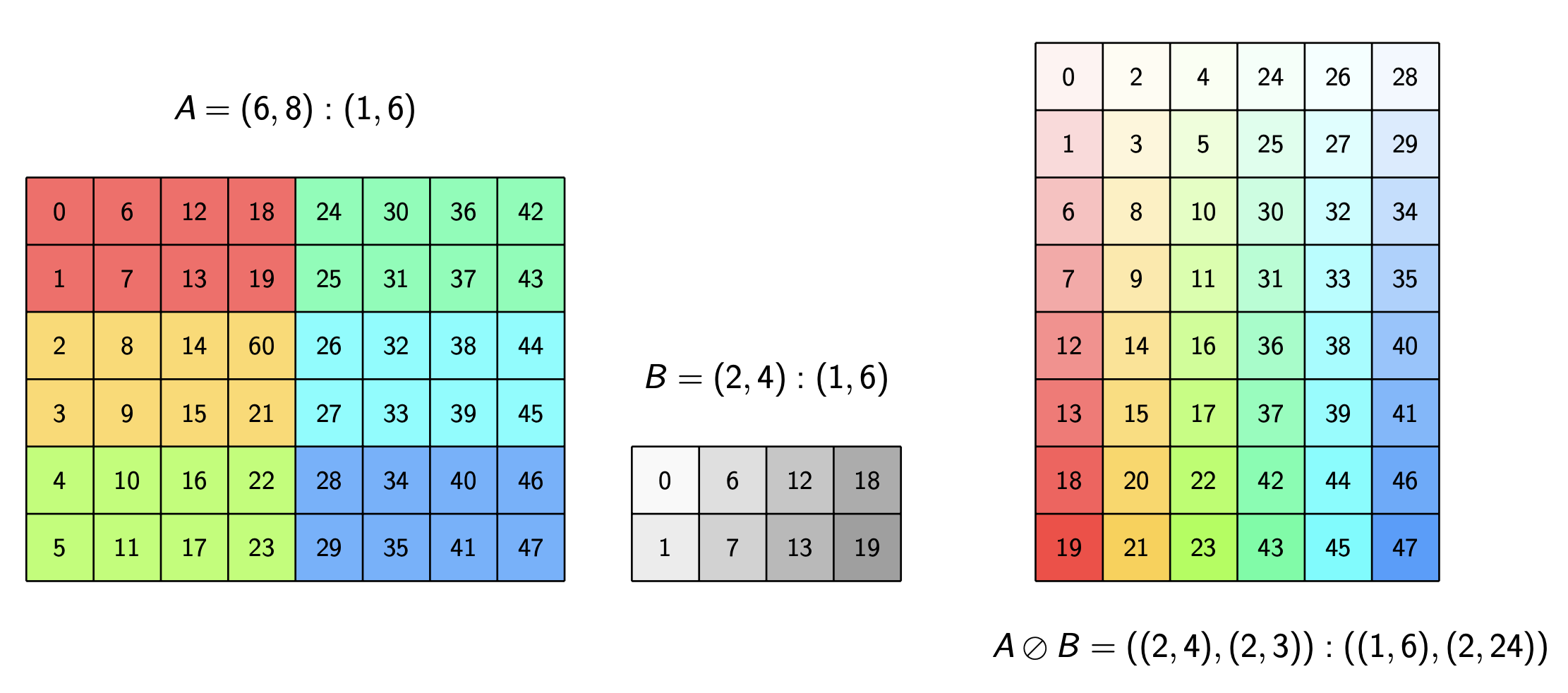
A note on the algebra of CuTe Layouts

The core abstraction of NVIDIA’s CUTLASS library for high-performance linear algebra is the CuTe Layout. In this technical note, we give a rigorous, mathematical treatment of the algebra of these layouts and certain layout operations. Currently, the main goal is to lay down conditions for when the operations of complementation, composition, and logical division are… Go to article…
-
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library
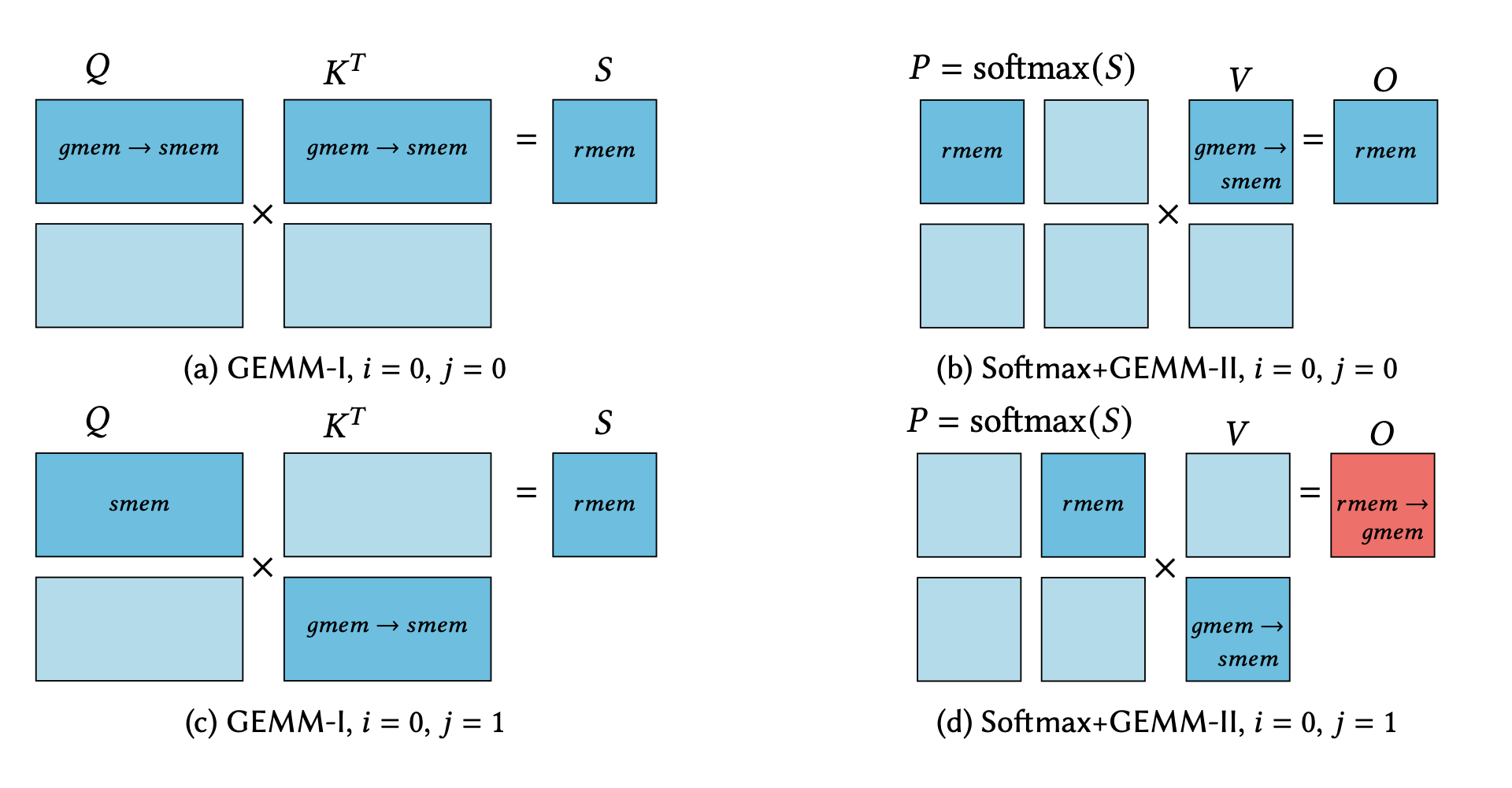
We provide an optimized implementation of the forward pass of FlashAttention-2, a popular memory-aware scaled dot-product attention algorithm, as a custom fused CUDA® kernel targeting NVIDIA Hopper™ architecture and written using the open-source CUTLASS library. In doing so, we explain the challenges and techniques involved in fusing online-softmax with back-to-back GEMM kernels, utilizing the Hopper-specific… Go to article…