Tag: GEMM
-
Sharing NVIDIA® GPUs at the System Level: Time-Sliced and MIG-Backed vGPUs
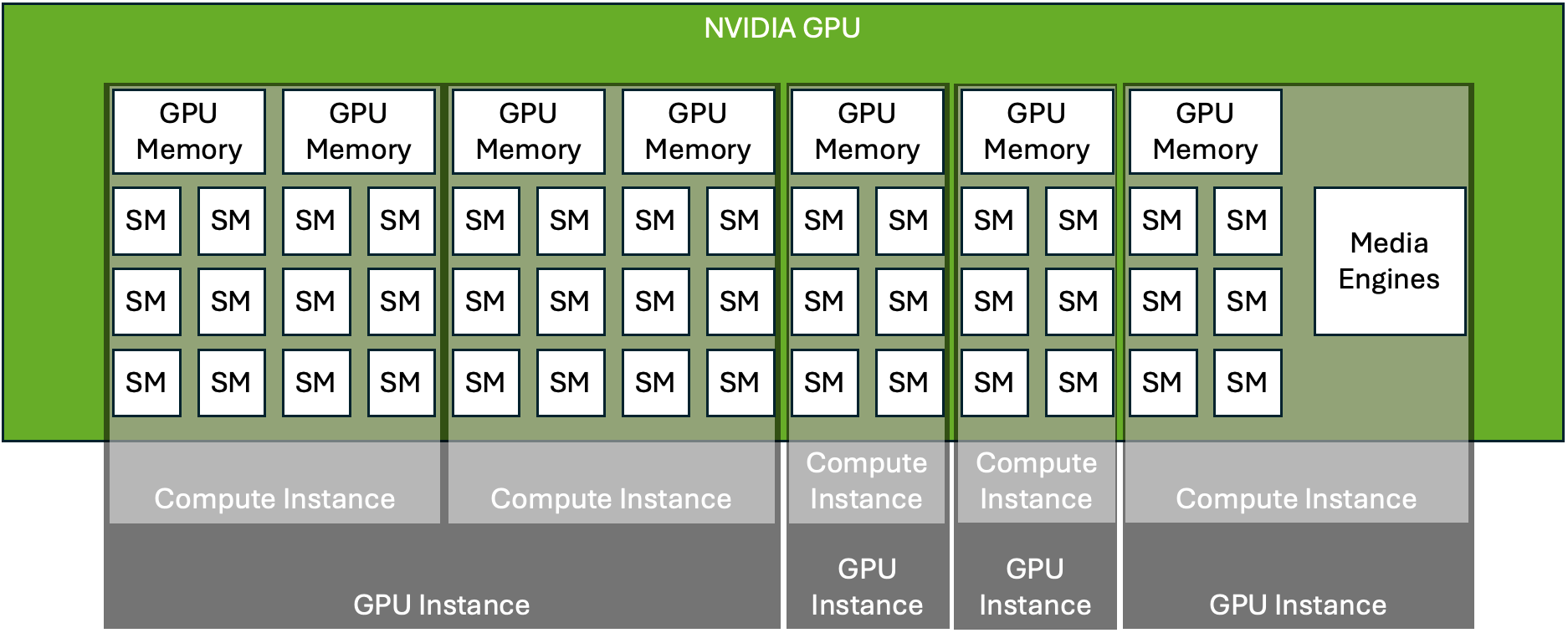
While some modern applications for GPUs aim to consume all GPU resources and even scale to multiple GPUs (deep learning training, for instance), other applications require only a fraction of GPU resources (like some deep learning inferencing) or don’t use GPUs all the time (for example, a developer working on an NVIDIA CUDA® application may Go to article…