Category: Tutorials
-
CUTLASS Tutorial: Hardware-supported Block-scaling with NVIDIA Blackwell GPUs

Welcome to part 4 of our series investigating GEMM on the NVIDIA Blackwell architecture. So far we have discussed the capabilities of the new Blackwell Tensor Core UMMA instructions, including handling sub-byte data types, and how to work with them in CUTLASS. In this part, we will continue our exploration of low-precision computation by discussing Go to article…
-
CUTLASS Tutorial: Sub-byte GEMM on NVIDIA® Blackwell GPUs
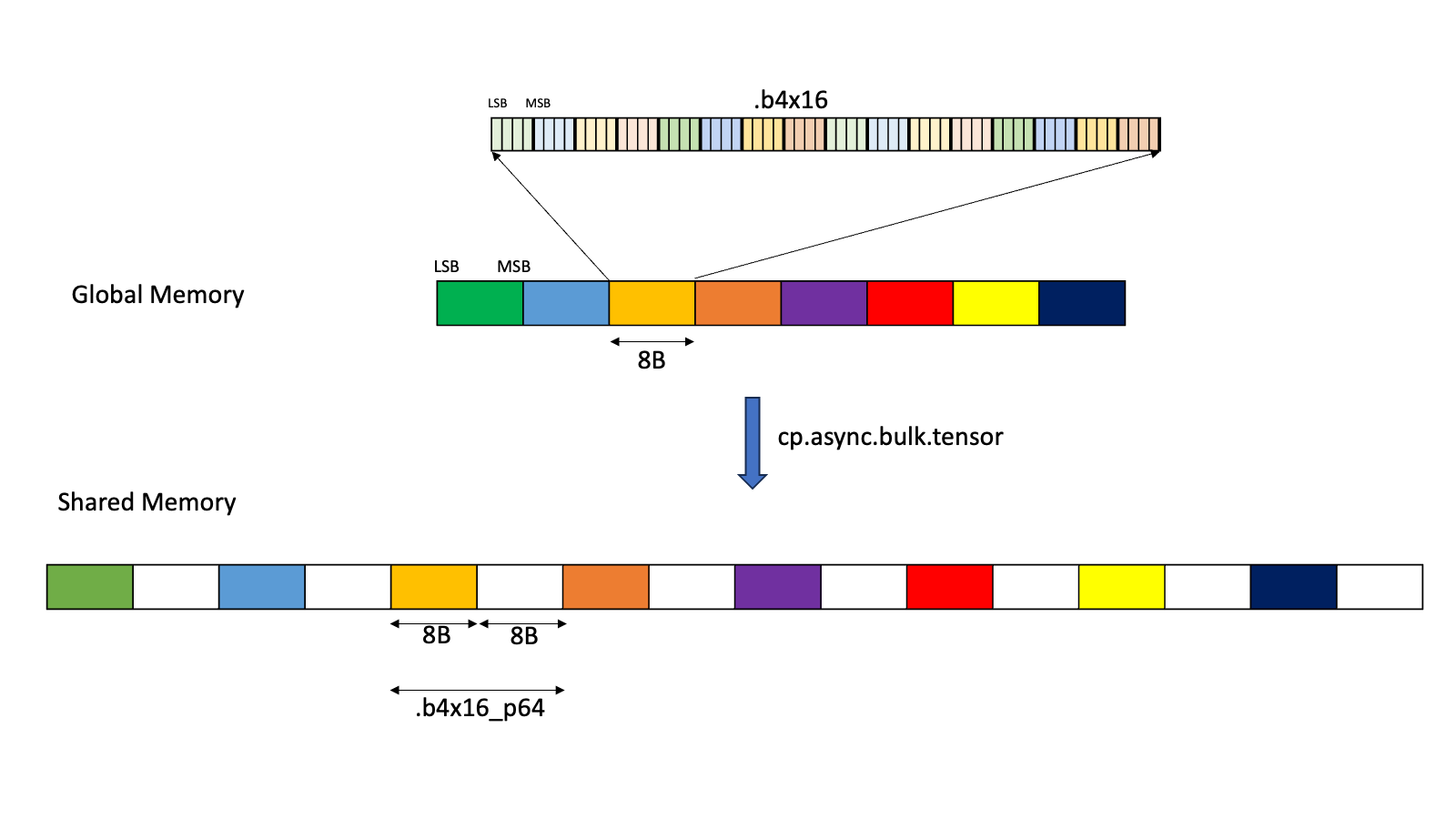
Welcome to part 3 of our series investigating GEMM on the NVIDIA Blackwell architecture. In parts 1 and 2, we looked at the Tensory Memory and 2 SM capabilities of the new Blackwell Tensor Core UMMA instructions and how to work with them in CUTLASS. In this part, we introduce low-precision computation and then discuss Go to article…
-
CUTLASS Tutorial: GEMM with Thread Block Clusters on NVIDIA® Blackwell GPUs
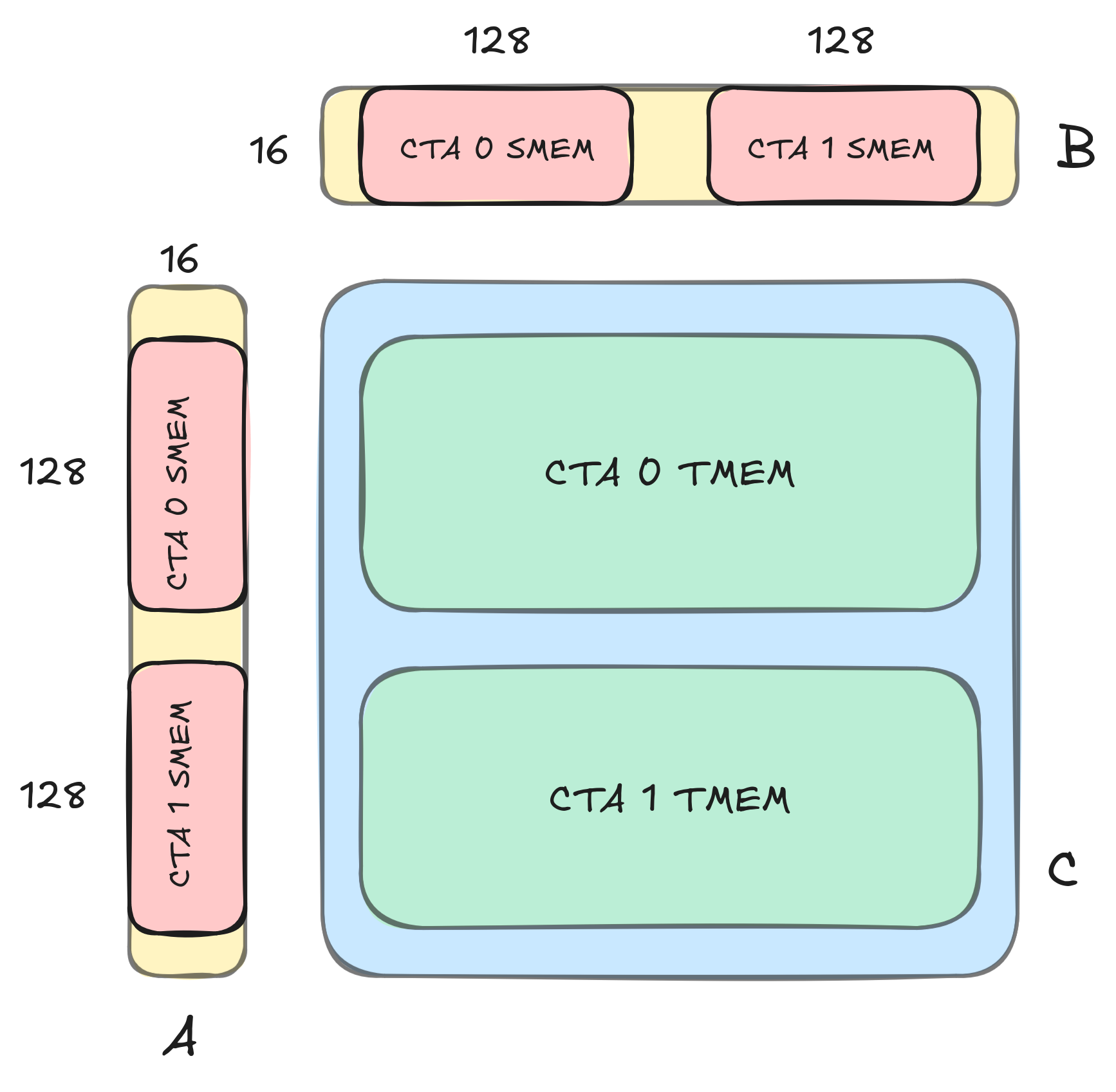
Welcome to part two of our series investigating GEMM on the NVIDIA Blackwell architecture. In part 1, we introduced some key new features available on NVIDIA Blackwell GPUs, including Tensor Memory, and went over how to write a simple CUTLASS GEMM kernel that uses the new UMMA instructions (tcgen05.mma) to target the Blackwell Tensor Cores. Go to article…
-
CUTLASS Tutorial: Writing GEMM Kernels Using Tensor Memory For NVIDIA® Blackwell GPUs
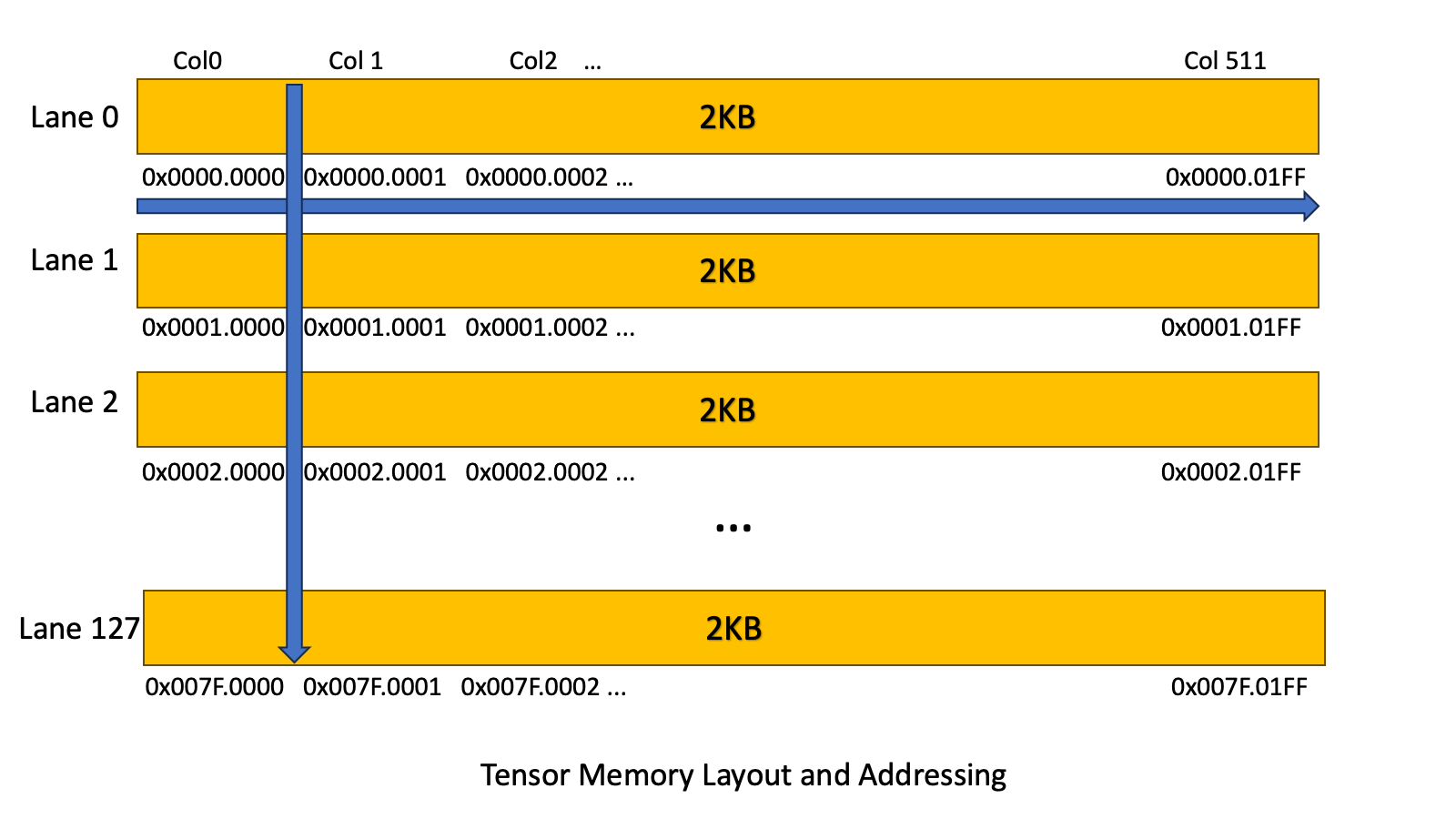
The NVIDIA Blackwell architecture introduces some new features that significantly change the shape of a GEMM kernel. In this series of posts, we explore the new features available on Blackwell and examine how to write CUTLASS GEMM kernels that utilize these new features by drawing on the CuTe tutorial examples. The goal of this series Go to article…
-
CUTLASS Tutorial: Persistent Kernels and Stream-K
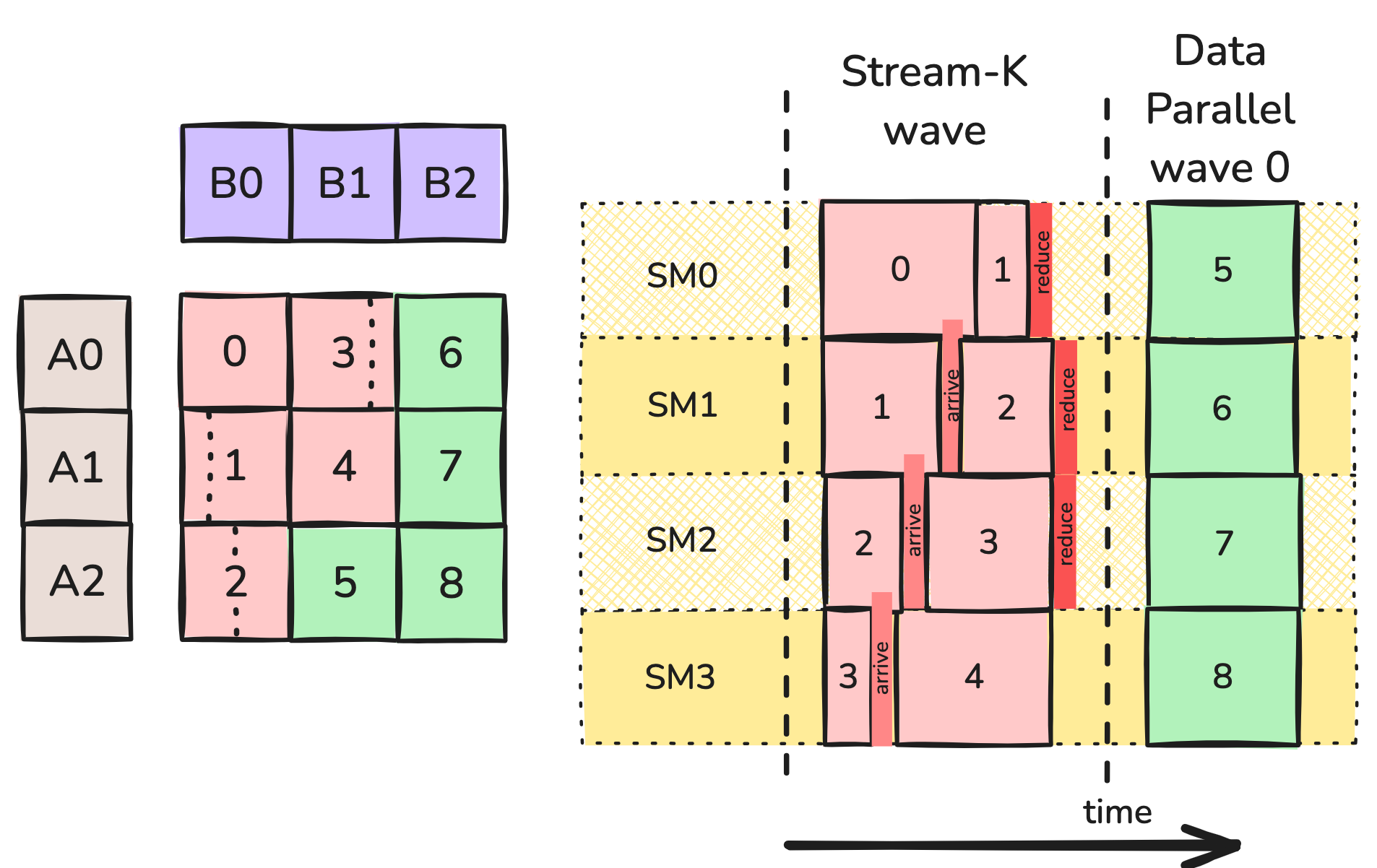
Welcome to Part 3 of our tutorial series on GEMM (GEneral Matrix Multiplication). In Parts 1 and 2, we discussed GEMM at length from the perspective of a single threadblock, introducing the WGMMA matmul primitive, pipelining, and warp specialization. In this part, we will examine GEMM from the perspective of the entire grid. At this Go to article…
-
Epilogue Fusion in CUTLASS with Epilogue Visitor Trees
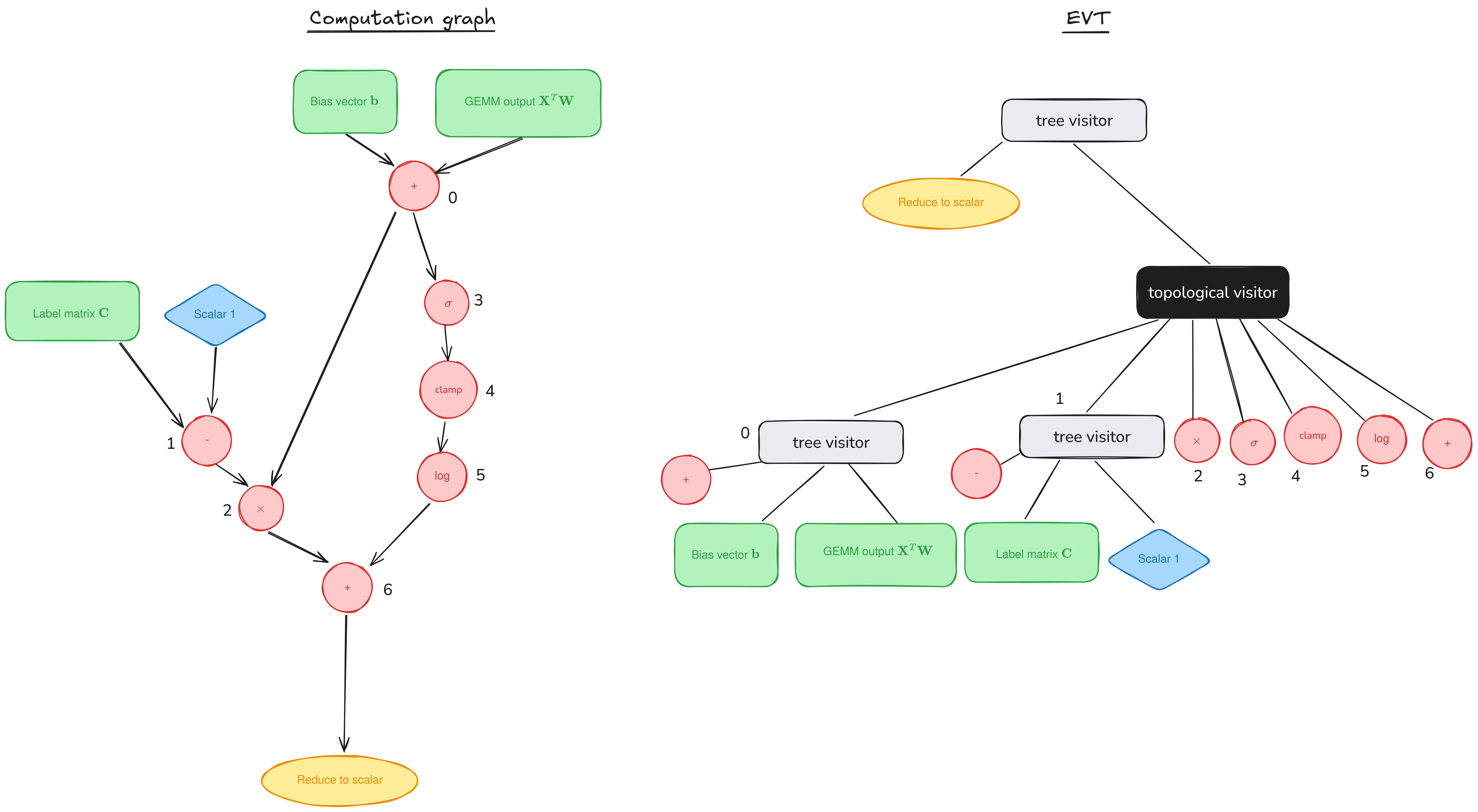
Welcome to a supplemental article for our tutorial series on GEMM (GEneral Matrix Multiplication). Posts in the main series (1, 2) have discussed performant implementations of GEMM on NVIDIA GPUs by looking at the mainloop, the part responsible for the actual GEMM computation. But the mainloop is only a part of the CUTLASS workload. In Go to article…
-
CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining
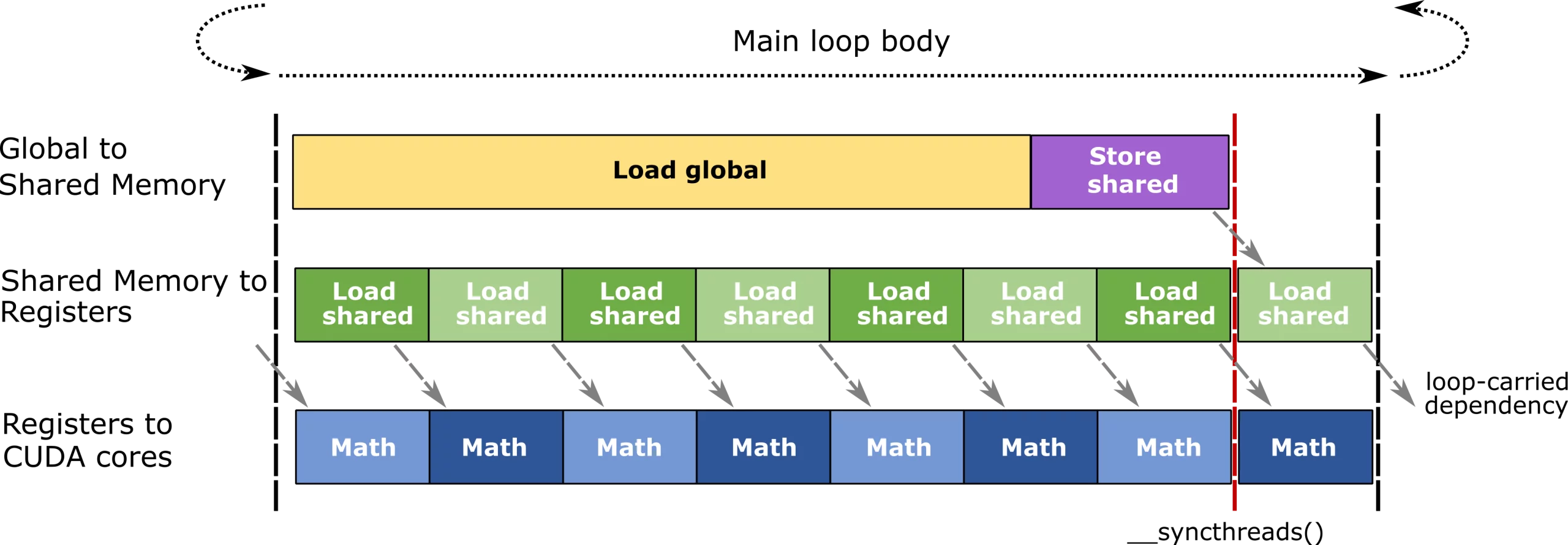
Welcome to Part 2 of our tutorial series on GEMM (GEneral Matrix Multiplication). In Part 1, we discussed the computational side of GEMM by going over WGMMA, which is the primitive instruction to multiply small matrix tiles on GPUs based on the NVIDIA® Hopper™ architecture. In this part, we turn our focus to the memory Go to article…
-
CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs
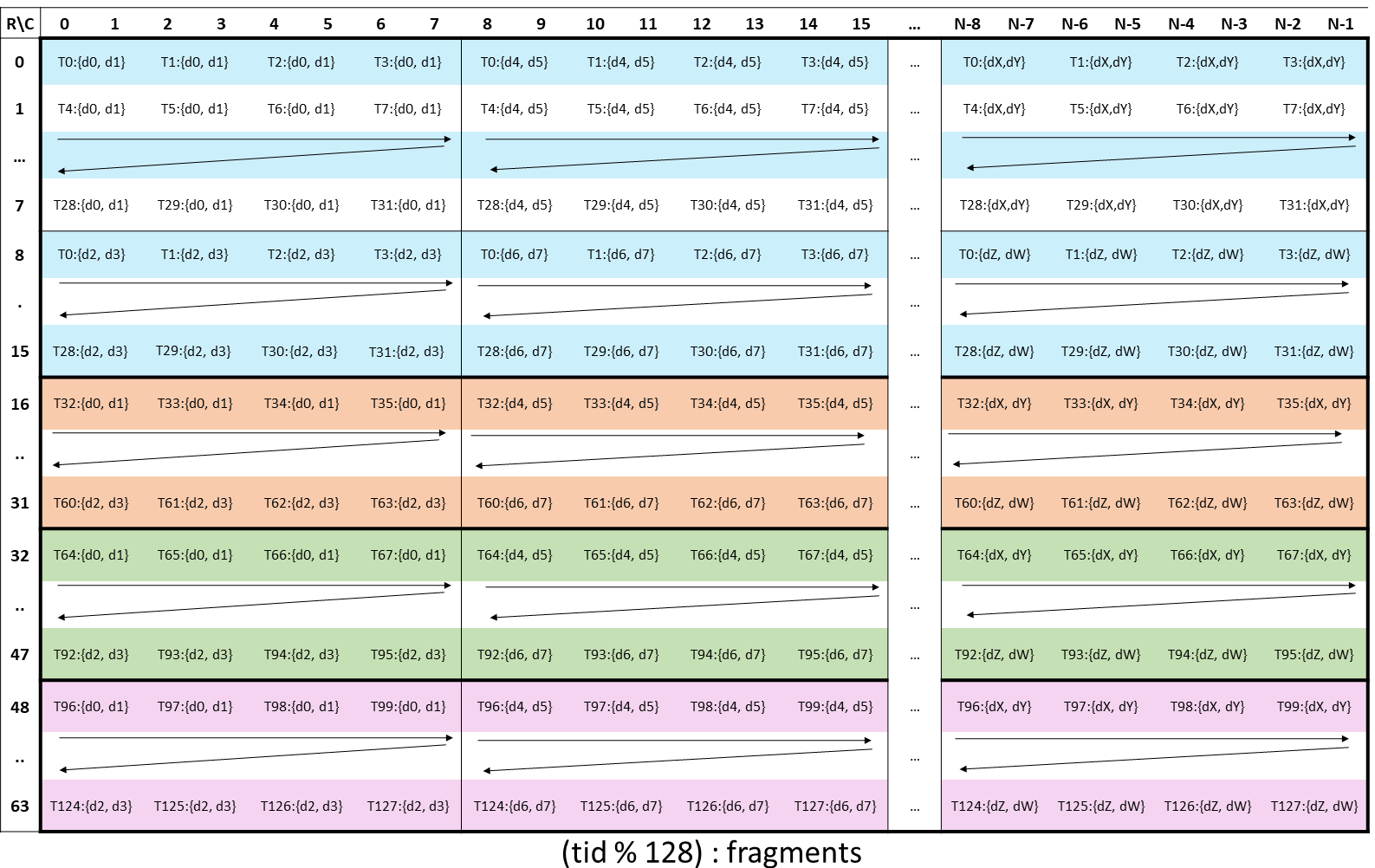
No series of CUDA® tutorials is complete without a section on GEMM (GEneral Matrix Multiplication). Arguably the most important routine on modern GPUs, GEMM constitutes the majority of compute done in neural networks, large language models, and many graphics applications. Despite its ubiquity, GEMM is notoriously hard to implement efficiently. This 3-part tutorial series aims Go to article…
-
CUTLASS Tutorial: Mastering the NVIDIA® Tensor Memory Accelerator (TMA)
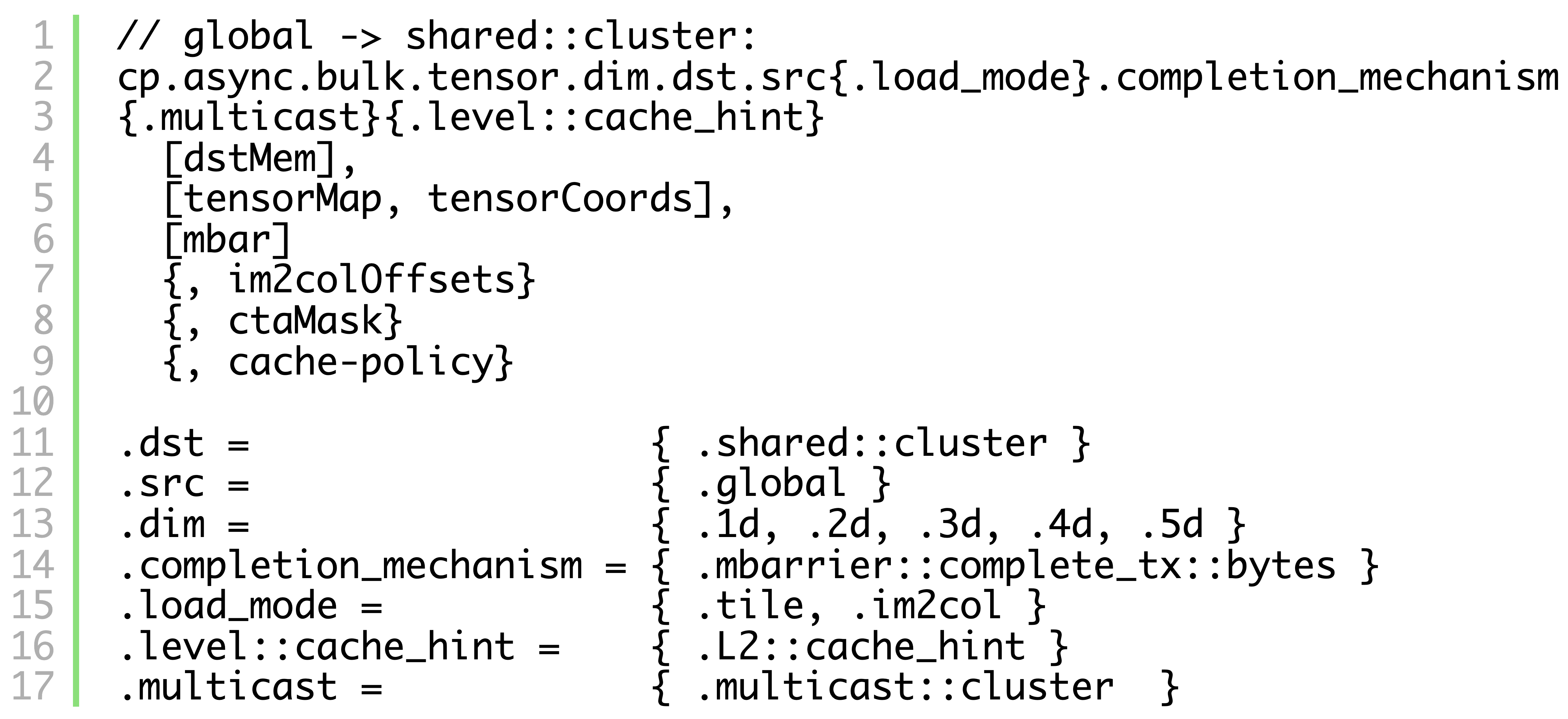
TMA (Tensor Memory Accelerator) is a new feature introduced in the NVIDIA Hopper™ architecture for doing asynchronous memory copy between a GPU’s global memory (GMEM) and the shared memory (SMEM) of its threadblocks (i.e., CTAs). Compared to prior approaches, TMA offers a number of advantages, such as (1) improving GPU utilization through facilitating warp-specialized kernel Go to article…
-
Tutorial: Matrix Transpose in CUTLASS
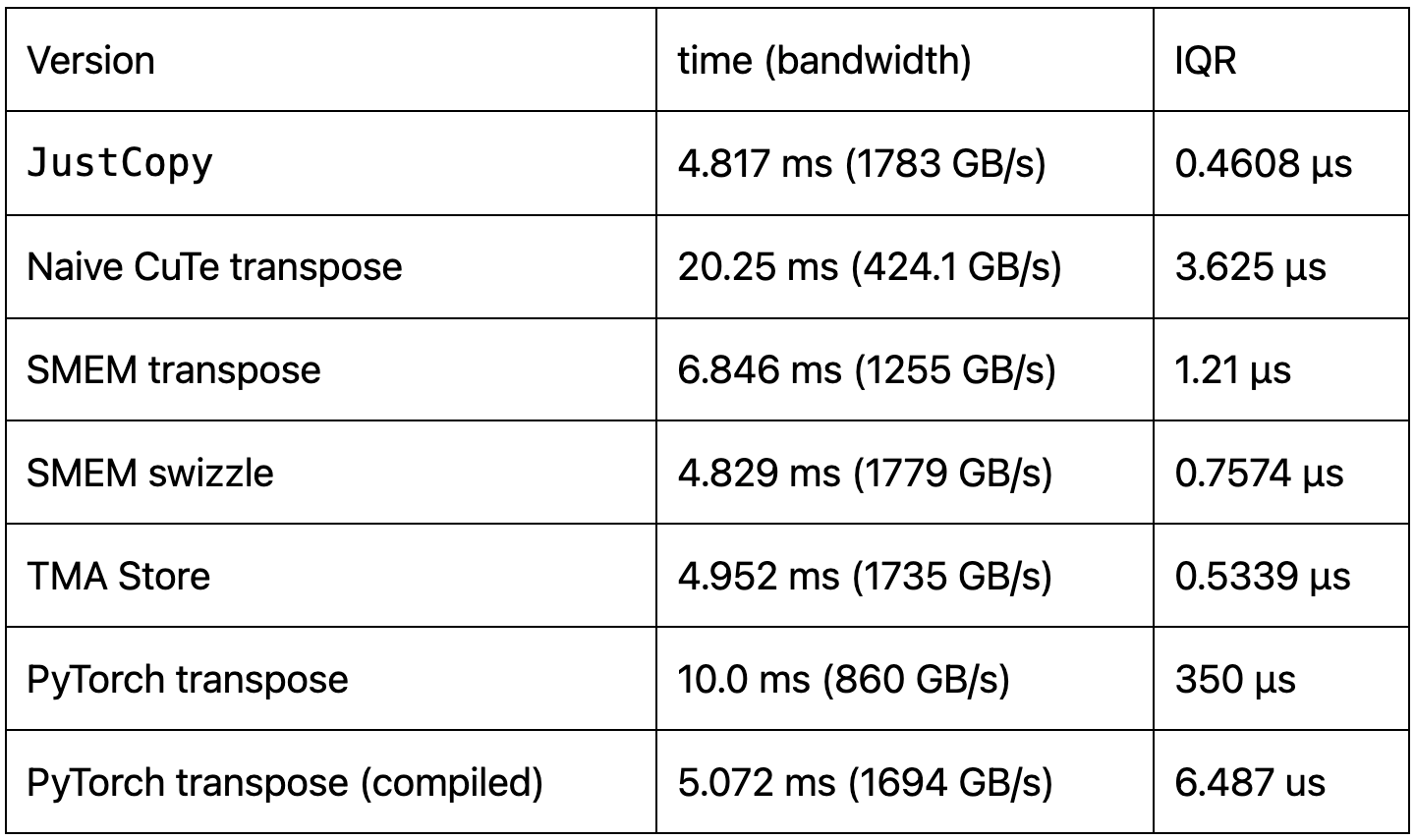
The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will study the task of matrix transpose as an illustrative example for these concepts. We choose this task because it involves no operation other than Go to article…